Data Lakehouse Explained: Building a Modern and Scalable Data Architecture
By John Bemenderfer
In this blog, we’ll break down what makes a data lakehouse unique, explain its architecture, and explore the potential benefits and challenges of adopting this modern data solution.
The data lakehouse represents a new way forward for data management, bringing together the best of both data lakes and data warehouses. By addressing the limitations of traditional architectures, it gives you a path to centralize, streamline, and fully leverage all your data.
A data lakehouse is a modern data management architecture that combines the low-cost, scalability, and flexibility of storing a diverse range of file types inherent to data lakes with the performance, governance, and reliability features of a data warehouse. A data lakehouse stands out because it:
Supports all file types by easily storing and analyzing structured and unstructured data — everything from traditional transaction data (csv, parquet, avro, etc.) to images, video, and text (png, mp4, txt, etc.).
Offers vendor flexibility by using open-source file formats like Apache Parquet, Iceberg and ORC, allowing you to work with different tools and vendors without the fear of being locked-in. These open-source file formats work seamlessly with compute engines like Spark, enabling data users — from business analysts to data scientists — to access data using languages such as SQL, Python, Scala, or R.
Ensures data quality by enforcing schemas and validation rules, guaranteeing that new data fits defined structures and maintains consistency.
Strengthens data governance through comprehensive access controls, detailed lineage tracking, rich metadata management, and granular audit trails, enabling easy visibility into data usage.
Scales storage and compute independently by decoupling the two, letting you scale independently based on your needs for more flexibility and cost control.
Supports business intelligence and real-time reporting by allowing BI tools to directly access data, keeping insights fresh and eliminating the need to duplicate data for different use cases.
Enables real-time analytics by capturing streaming data, so you can generate insights as data arrives.
Primes AI adoption by unifying diverse data types with rich metadata, supporting dynamic compute resources from CPUs to specialized AI accelerators, and enforcing enterprise-grade security controls to accelerate AI initiatives.
Ensures data reliability with ACID transaction support by maintaining consistency and integrity through:
Atomicity, where each transaction completes in full or not at all, preventing partial data.
Consistency, where data changes follow predictable rules, protecting data quality.
Isolation, where multiple users can work with data simultaneously without interference.
Durability, where completed transactions are permanently saved, even with a system failure.
How is a Data Lakehouse Different than a Data Warehouse or Data Lake?
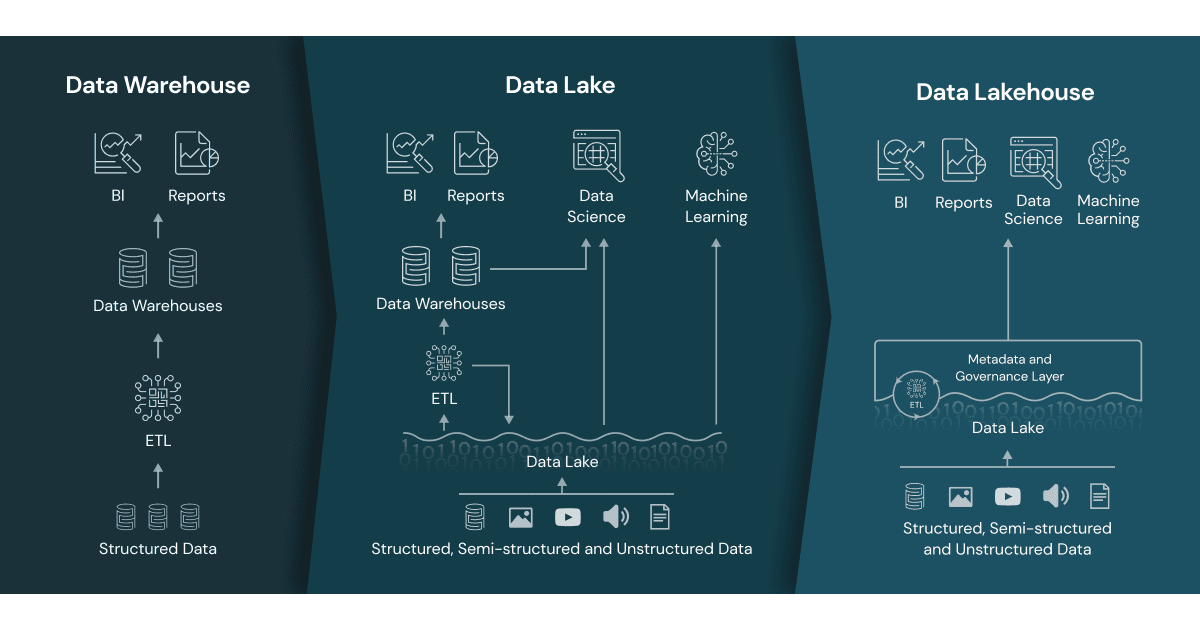
A data lakehouse combines the strengths of both warehouses and data lakes, giving you unified data storage without sacrificing structure or flexibility.
Unlike a data warehouse, it can affordably store raw, unstructured data. Unlike a data lake, it supports reliable data management, making it easier to analyze and query data when you need it.
A data lakehouse is designed to address the limitations of the data warehouse by allowing low-cost storage for raw data while allowing for managed and query optimized data not achievable in a data lake. Photo credit: Databricks
What is a Data Warehouse
Data warehouses have been a mainstay in data management since the 1980s. They serve as centralized relational databases that consolidate data from various sources into a structured schema, ideal for business intelligence and reporting. Data warehouses often contain “golden records” because they cleanse and combine data from multiple sources, creating a comprehensive and reliable dataset for reporting.
Limitations of the Data Warehouse
Despite their strengths, data warehouses come with several key limitations:
High cost for massive data volumes
Limited ability to handle unstructured or semi-structured data
Inability to process streaming data efficiently
Significant work to introduce new data sources
What is a Data Lake
Data lakes emerged in the 2010s to address these limitations by providing a low-cost solution for storing massive amounts of raw data in open file formats. Unlike data warehouses, data lakes don’t enforce schema on data when it’s stored. Instead, they apply schema on read, allowing for flexible storage of diverse types, including video, text files, images, and audio. This structure makes data lakes well-suited for big data, artificial intelligence, and machine learning applications.
Limitations of the Data Lake
Despite their flexibility, data lakes also present challenges:
Require additional tools to support SQL queries for business intelligence
Struggle with data quality and data governance
Lack of robust security and access control
Disorganized data resulting in stale unused data
Combining Strengths of Each with the Data Lakehouse
Many organizations attempt to bridge these limitations by using a two-tiered system, extracting data from data lakes into a data warehouse for business intelligence. However, the data lakehouse offers a streamlined alternative to this approach by integrating the strengths of both warehouses and data lakes in a single architecture.
Hear from Tony about the difference between these three concepts
How a Data Lakehouse Improves on the Data Warehouse and Data Lake
The data lakehouse offers a unified approach that provides distinct advantages, including:
Enhanced data quality and reliability: Schema enforcement and centralized data storage improve data, while built-in data governance capabilities make it easier to track data lineage and ensure compliance.
Cost-efficient storage: A data lakehouse stores all data — structured and unstructured — in one place, reducing costs associated with data silos resulting in the need to manage multiple storage solutions.
Integrated support for BI and advanced analytics: Open file formats allow seamless use of data across business intelligence tools, machine learning, and AI, enabling a comprehensive view of your data for both operational and strategic insights.
Reduced redundancy: By centralizing data storage, the lakehouse minimizes the need for duplication, simplifying data management and reducing complexity.
Flexible, unified data access: Access structured and unstructured data in one place, enabling faster, more versatile analysis for a range of workloads, from daily reporting to advanced modeling.
Open architecture with vendor flexibility: Open file formats like Apache Parquet, Iceberg, and OCR allow you to adapt to changing needs, avoiding vendor lock-in and enabling integration with various tools as your technology stack evolves.
Defining a Data Lakehouse Architecture
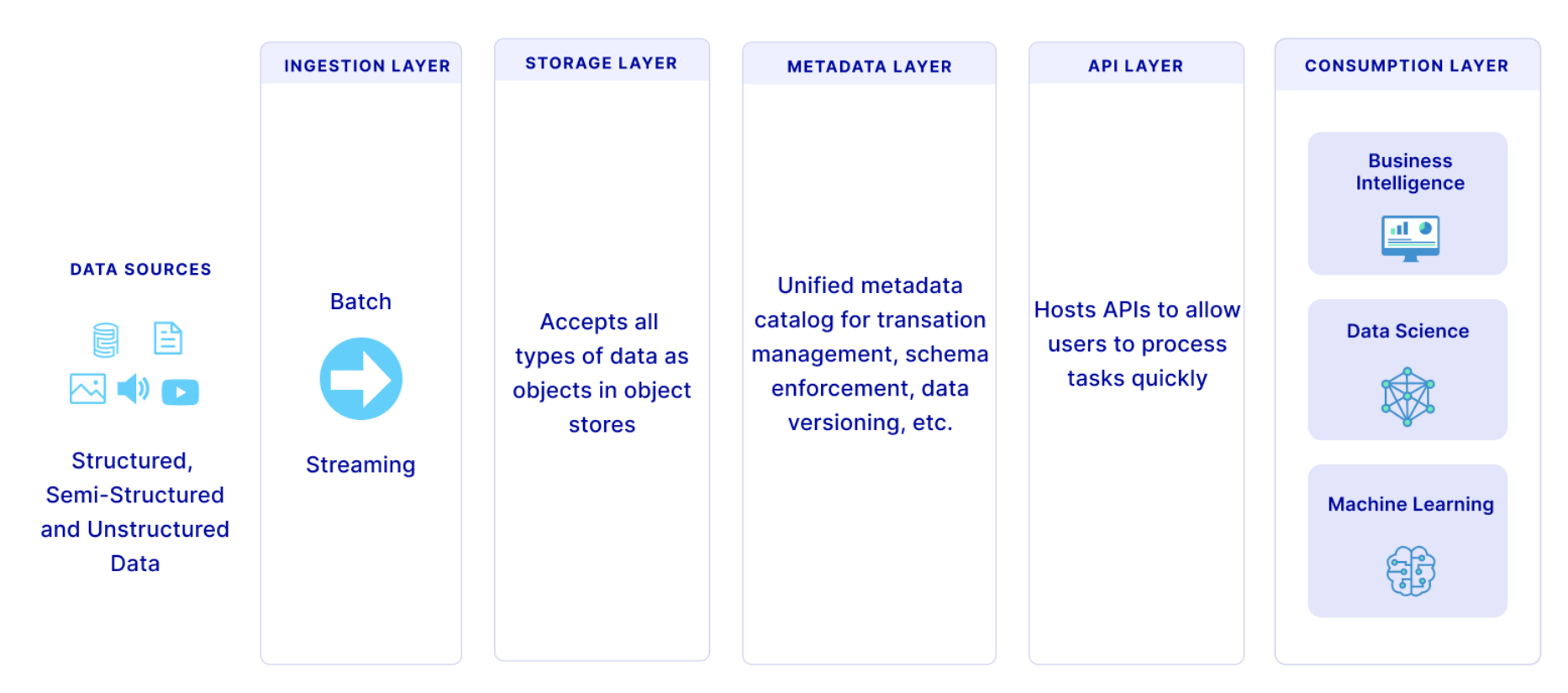
The data lakehouse architecture integrates multiple layers, each designed to support efficient data storage, management, and access in a unified system.
The data lakehouse architecture consists of five distinct layers, including ingestion, storage, metadata, API, and consumption layers. Each play a key role in making the data lakehouse a modern data architecture. Image credit: Striim
Ingestion layer: Pulls in data from various sources, including streaming data and transactional batch loads. This layer handles structured, semi-structured, and unstructured data through various protocols and tools.
Storage layer: Stores large volumes of data at low-cost, using open file format like Parquet. The storage layer accommodates structured, semi-structured, and unstructured data, making it accessible for machine learning and AI applications. For improved performance, consider partitioned formats like DELTA or ICEBERG, which support file compression and optimized querying.
The metadata layer: Adds warehouse-like features to the data lakehouse by managing essential metadata. This layer includes:
ACID transactions for data integrity, consistency, and reliability.
Schema governance to ensure data quality.
Indexing to enhance data retrieval and performance.
Caching for faster access to frequently used data.
Time travel to access to historical data or restore previous versions.
Access control to protect data with user-based permissions.
API layer: Enables efficient data access for various tools and applications. Open data formats allow direct integration with machine learning, advanced analytics, and other software, making data easily accessible for a range of use cases.
Consumption layer: Supports business intelligence and data analysis by allowing direct access from BI tools like Power BI and Tableau, as well as supporting SQL queries and machine learning workflows.
The lakehouse architecture also decouples storage and compute, giving you the flexibility to scale each independently. By using separate clusters for storage and compute, you can adjust resources based on business needs while controlling costs. Monitoring and optimizing compute usage helps prevent unnecessary expenses as workloads grow.
Which Technologies Offer a Data Lakehouse and What are Other Options on the Market?
You have options to adopt a strict “out-of-the-box” data lakehouse with a technology like Databricks, or you can use other vendors you might already be invested in which offer the same benefits of a data lakehouse using slightly different architectures.
Databricks is leading the data lakehouse space with Delta Lake — which is an open format storage layer that delivers reliability, security, and performance for a data lake. Due to the open nature of Delta Lake, it can be used with AWS, Azure, or GCP. It uses open-source technology which may be appealing to certain organizations.
Snowflake allows for many of the features and capabilities that make up the data lakehouse architecture. While Snowflake does not have a traditional data lake, it can act as one with its micro-partitioning, essentially providing similar capabilities. Snowflake does use proprietary technologies which makes it more difficult to move to another system should the need arise. This proprietary storage and metadata layer removes the open-source feature of a pure data lakehouse architecture, but it is, within the Snowflake environment, functionally the same.
Azure Synapse Analytics coupled with Azure Data Lake allows for many of the features and capabilities of the data lakehouse architecture. Azure Synapse Analytics is a fully managed petabyte-scale cloud-based data warehouse product designed for large-scale dataset storage and analysis. Synapse has the capabilities of connecting to a data lake, providing many of the capabilities of the data lakehouse, but this removes the open-source feature of a pure data lakehouse architecture. Just like Snowflake, however, in Synapse is it functionally the same.
Amazon Redshift coupled with Amazon S3 allows for many of the features and capabilities of the data lakehouse architecture. Amazon Redshift is a fully managed petabyte-scale cloud-based data warehouse product designed for large-scale data set storage and analysis. Redshift can sit on top an Amazon S3 instance and provide query capabilities for BI and advanced analytical needs. Like other solutions, Amazon Redshift is built using proprietary technology, it is not open-source and doesn’t follow the “rule book” definition but provides most of the key features found in the data lakehouse architecture. This makes it a great solution for any business or organization looking to build a data lakehouse.
This list isn’t exhaustive and there are other vendors that provide other solutions for the data lakehouse architecture. It’s also important to note that the architecture for a data lakehouse allows for mixing of technologies from different providers. For instance, you can have an Amazon S3 instance with a Databricks Delta Lake acting as the metadata layer.
How to Successfully Migrate from a Data Warehouse or Data Lake to a Data Lakehouse
Migrating from a data warehouse to a data lakehouse opens the door to greater flexibility, scalability, and efficiency — but it requires careful planning. Here are key steps and tips to ensure a smooth migration:
Simplify Configuration and Access Control: Define security policies early to handle the new access control layers in the lakehouse environment. Use role-based access controls (RBAC) to assign permissions effectively. Automate cluster configuration for consistent setup and consider consulting experienced architects to streamline this process.
Optimize Compute Engine Start-Up Times: Automate spin-up processes for compute engines and clusters to minimize delays. Use serverless options, where available, to avoid idle compute costs and improve responsiveness. Set clear expectations with users about start-up times to prevent frustration.
Ensure High Data Quality: Establish a robust governance framework with clear validation processes. Use tools like Delta Lake or Apache Iceberg to enforce schema governance and maintain data quality. Automate testing workflows to catch inconsistencies early in the process.
Manage Costs Effectively: Monitor resource usage regularly to avoid unexpected expenses. Use scaling policies to adjust compute and storage resources dynamically based on workload demands. Right-size your clusters for each stage of the migration process, starting small and scaling as needed.
Start with Incremental Workloads: Instead of migrating everything at once, start with a single workload or dataset. Test your lakehouse’s performance and scalability with manageable data sizes, then expand once you’ve fine-tuned the architecture.
Leverage Open Formats and Tools: Use open-source file formats like Apache Parquet or Delta Lake for maximum flexibility. These formats make it easier to integrate tools like Spark or Presto while avoiding vendor lock-in. Standardize on formats and protocols that align with your long-term analytics goals.
Prepare for Diverse Data Types: Unlike traditional data warehouses, lakehouses support structured, semi-structured, and unstructured data. Take inventory of your current and future data types, and select tools optimized for handling these formats.
Is The Data Lakehouse Solution Right for Your Business?
A data lakehouse may be the right choice for your organization if you want to:
Perform both BI and advanced analytics. Analyze structured data with tools like Power BI or Tableau and access datasets optimized for machine learning and AI — all within one system.
Reduce data redundancy. Stop replicating data across multiple lakes, warehouses, or marts. Instead, store everything in one centralized location.
Simplify data observability. Minimize data movement and the complexity of pipelines by consolidating your data into one open-format system.
Simplifyyour data management. Replace multi-tiered architectures with a single, unified solution that’s easier to manage.
Improve data security. Apply access controls to protect sensitive data, including machine learning and AI workflows.
Add flexibilityto your analytics. Adapt storage, metadata, or consumption layers as your business needs evolve, thanks to open-source formats and APIs.
Lower storage cost. Store raw data — from CSVs to audio and video — at low cost while scaling to match your organization’s growth.
While this is not an exhaustive list, it helps to start the conversation on whether a data lakehouse is a good solution for your organization.
Talk With a Data Analytics Expert
Key Takeaways
A data lakehouse combines the scalability of a data lake with the structure and reliability of a data warehouse.
It supports diverse data types and open file formats, enabling vendor flexibility and real-time analytics.
Lakehouses improve data quality, governance, and cost efficiency by unifying storage and compute across all data.
The architecture includes layers for ingestion, storage, metadata, APIs, and consumption to streamline data operations.
Technologies like Databricks, Snowflake, Azure Synapse, and Redshift offer lakehouse capabilities, with varying degrees of openness.
Migrating to a lakehouse requires careful planning around governance, compute optimization, and incremental adoption.
Lakehouses are ideal for businesses seeking to unify BI and AI, simplify data pipelines, and reduce overall storage and processing costs.
John is a Managing Consultant based in our Dallas office. He brings broad expertise across the entire data stack—from data engineering and analytics to generative AI—helping clients unlock real value from their data. Outside of work, John enjoys spending time with his wife, daughter, and son, diving into Dungeons & Dragons campaigns, and all things Star Wars.
Do you make business decisions based on spreadsheets or siloed databases with non-standardized structures and formats? Do you see inconsistency in data across business units? Do you have difficulties deciding permissions and access levels to restricted business data? In this blog, we discuss how these problems can be addressed with a data warehouse and provide…
For your analytics solution to effectively drive decision making, you need clean data and a flexible data infrastructure that supports all of your current and future analytics needs. Everything you want to do when it comes to analytics – from the advanced stuff, like data science and machine learning, to the basics – hinges on…
In this blog, we provide insight as to why manual data practices can bring unnecessary risk to your projects and how to overcome those obstacles. Why Manual Processes Aren’t “Good Enough” While every analyst knows that automation practices lead to better data quality, more accurate reporting, and ultimately the ability for them to focus on…
To prevent data breaches entirely is very difficult, but following these practices will help minimize risk and vulnerabilities. Increased Data Usage = Increased Risk With the increasing popularity of smartphones, conducting online transactions, and social media, the amount of data that gets collected and stored each day is truly astounding. It is estimated that 2.5…
During a Q&A session with Analytics8 CTO, Patrick Vinton, he discusses industry trends and shares insights into how companies are—and should be—facing topical challenges. Discussion topics include: the urgency of cloud adoption, how COVID-19 is affecting business behaviors, how to face these challenges, and opportunities stemming from the blurred lines between traditional and advanced analytics….
Why you should be moving your data and analytics assets to the cloud and three things to do to get started. If a significant number of your business applications are not currently in the cloud, I guarantee that you are struggling right now to equip your employees to work from home. You’ll be dealing with…
Data Strategy Session
To thrive with your data, your people, processes, and technology must all be data-focused. This may sound daunting, but we can help you get there. Sign up to meet with one of our analytics experts who will review your data struggles and help map out steps to achieve data-driven decision making.
Fill out this form to get a 30-minute Data Strategy Session with one of our analytics experts.
Contact Us
Have questions? Tell us a little about yourself, and we'll get in touch as soon as we can.