Databricks Lakehouse: Solving Today’s Data Engineering Challenges
By David Walborn
Managing the entire lifecycle of your data — from ingestion and engineering to analytics and machine learning — can be overwhelming, especially when you’re dealing with fragmented tools, inefficient pipelines, and complex workflows.
The Databricks Lakehouse architecture simplifies this by combining the flexibility of data lakes with the performance of data warehouses into a unified platform. This approach allows you to streamline operations, accelerate data pipelines, ensure strong data governance, and harness machine learning, all while maintaining the adaptability your organization needs to tackle complex data challenges.
How to Integrate Databricks fit into a Modern Data Architecture
While modern data architectures can vary in their patterns and technologies, the foundational elements of a modern data architecture are grounded on three basic elements:
ELT (extract/load/transform): This involves ingesting of all data into a central staging area (a data lake). The data is stored in its raw form, creating an un-curated data layer they can be accessed for lineage tracing or ad-hoc development.
ETL (extract/transform/load): Here, the raw data is transformed into a dimensionally modeled format, usually within a data warehouse. This process creates a curated data layer, which serves as the source of truth for your org.
Analytics/Reporting: This is where users access the curated data. While Databricks plays a critical role in data preparation and processing, it’s important to note that it is not designed as a replacement for dedicated data visualization tools like Power BI, Tableau, or Qlik.
These elements define how data is ingested, prepared, and made available for use. While note exhaustive, they help clarify where Databricks and the Lakehouse architecture fit within a modern data ecosystem.
Specifically, the Databricks Lakehouse excels as a data engineering solution for both ELT and ETL tasks.
If you already have a cloud-based data warehouse, Databricks can be seamlessly integrated into your data architecture. It facilitates the movement and transformation of data from the source to the warehouse, and in some cases to the analytics/reporting layer.
Note: While Databricks also offers advanced features for more than just data plumbing — such as governance, machine learning/AI, and BI — this blog focuses on clarifying how the Lakehouse architecture simplifies and enhances your data engineering efforts.
How to Leverage the Databricks Lakehouse
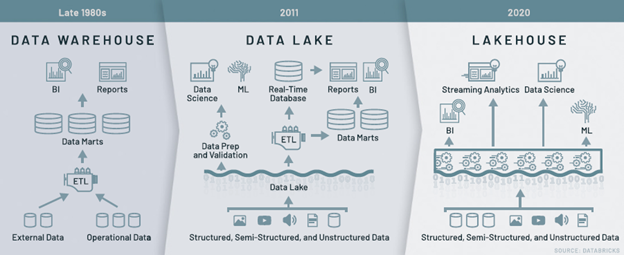
The Databricks Lakehouse architecture serves a dual purpose: it handles both compute tasks (ELT/ETL) and storage (data lake/data warehouse). This architecture combines the strengths of data lakes and data warehouses, enabling users to perform business intelligence, SQL analytics, data science, and machine learning on a single platform.
A lakehouse blurs the lines between traditionally separate solutions — data warehouses, data lakes, and ETL processes — creating a one-platform solution for modern data architectures. Photo: Databricks
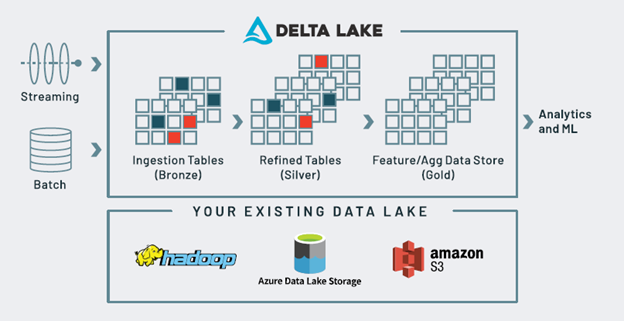
The core of the Lakehouse architecture is the Delta Lake, which addresses data reliability issues in traditional data lakes, such as transaction support, data quality enforcement, consistency, and data isolation.
Delta Lake on Databricks allows you to configure data lakes based on your workload patterns, providing optimized layouts and indexes for fast, interactive queries. It builds on top of object storage, simplifying the construction of big data pipelines and increasing their overall efficiency.
The foundation of the Lakehouse approach is the decoupling of storage and compute. A Databricks Delta Lake leverages your existing data lake to offer an organized, reliable, and efficient source of truth. Photo: Databricks
While other data platforms also separate storage and compute, and use the bronze, silver, and gold data storage layers (known as a medallion architecture), the Databricks Lakehouse stands out for its flexibility in operating transformations directly in your existing cloud storage or data lakes.
Adopting the full Lakehouse architecture isn’t necessary to benefit from the Databricks platform. Use Databricks in the way that best suits your specific needs and internal capabilities. You don’t need a cutting-edge data architecture to improve your data processes and gain transformative insights — focus on building a scalable system tailored to your needs.
How to Differentiate Databricks from Other Tools
When it comes to integrating, cleaning, de-duplicating, and transforming your data, or building machine learning applications, Databricks stands out from the competition. Why?
Barrier to Entry: Compared to many other ETL tools, Databricks allows engineers to hit the ground running by enabling them to write code in the language of their choice. There is no proprietary ‘Databricks scripting language’ to learn, which could become obsolete over time. This flexibility makes it easier to grow any development team.
Open Source: Databricks’ emphasis on open-source technology is a significant advantage. Data engineers can access open-source software libraries like Koalas (think pandas but distributed in the Apache architecture). Data scientists can use familiar packages like TensorFlow, PyTorch, or scikit-learn. Databricks is committed to the open-source community, as evidenced by their decision to open-source Unity Catalog (their data cataloging tool).
Interface: The notebook interface in Databricks makes it effortless to collaborate with other developers on the same code. The ability to work together in real-time on the same notebook enhances pair-programming and makes debugging sessions far more efficient.
A Data Engineer’s Advice for an Optimal Databricks Implementation
As powerful as Databricks is, it’s essential to approach its implementation with a clear strategy. Databricks can unlock significant insights and scale with your organization, but there are a few key considerations to keep in mind to ensure you’re getting the most out of the platform.
Let’s explore some critical aspects that will help you avoid common pitfalls and make the most of what Databricks has to offer:
Do the Basic Stuff First: Don’t be tempted by the allure of machine learning right away. Ensure you have a clearly defined curated layer of descriptive data. If you can’t accurately identify your sales numbers and their location, you certainly can’t write a machine learning program to forecast future sales accurately. The operational value of descriptive data will often outweigh any predictive mechanism. Focus on building a strong foundation before moving on to advanced capabilities.
Data Flow: A wise colleague once told me: data should only flow in one direction — source to target. When data flows in the opposite direction, ambiguity about the lineage is introduced. If the flow of data becomes multidirectional, control of the environment can be easily lost. Define the ideal data flow, and consider implementing data lineage, cataloging, and governance tools like Unity Catalog early in your Databricks implementation to avoid future complications.
Process Control: Your team may have written a beautiful symphony of code that performs all the tasks you need, but how can you be sure the data science team’s jobs kick off in sync with the completion of data engineering jobs? Who’s conducting this orchestra? In the same vein as data flow — you should understand how your Databricks scripts will be orchestrated. While Databricks offers native orchestration capabilities, it might be beneficial to use an external tool to coordinate all the Databricks jobs in some cases.
Enablement: Databricks is not a GUI-driven software. Ultimately, your data engineers and data scientists will be writing code unique to your use cases. Databricks is simply the vehicle to create, store, and execute said code. Consider whether you have the internal expertise to properly use Databricks. Are your data engineers empowered to write clean and efficient code? Do you have documentation in place in case of transition? Investing in talent and Databricks is not an either-or decision — both are crucial for success.
Get Started with Databricks Resources
Interested in learning more? There are many places you can get started with Databricks — but we’ve cherry picked some of our favorites:
Databricks Community Edition: The best place to get started is to create a free Databricks community account. This will let you spin up a small cluster to play around and get familiar with some Databricks basics. It’s great to play around in Databricks on your own, however we recommend using this in conjunction with some kind of online course (see below).
Free YouTube Databricks Overview: This video by Adam Marczak provides a clear and concise summary of how to get up and running with Databricks quickly.
Databricks Academy: The best resource we’ve found for learning Databricks is hands-down the Databricks Academy. These courses are put together by Databricks themselves and are designed to get you ready to use Databricks in a business environment. Note that while there are some free courses, much of the training available here is not cheap.
Databricks Community: The community page is an excellent resource to see what other users are doing with Databricks and can be a great first place to go with any technical questions.
Databricks Data Engineering Blog: Databricks’ own blog has a ton of excellent solutions laid out for how to get the most out of Databricks.
Talk With a Data Analytics Expert
Key Takeaways
Databricks Lakehouse architecture combines data lakes and data warehouses to streamline data operations and enhance machine learning capabilities.
Integrating Databricks into a modern data architecture involves using it for both ELT and ETL processes, making data available for analytics and reporting.
The Lakehouse architecture allows users to perform business intelligence and machine learning on one platform by blending the flexibility of data lakes with the efficiency of data warehouses.
Key advantages of Databricks include its open-source emphasis, flexible language support, and collaborative notebook interface.
Successful implementation of Databricks requires a strategic approach, focusing on a strong data foundation and clear data flow.
Orchestration and enablement are crucial for ensuring that Databricks integrates effectively with your existing data workflows.
There are numerous resources to get started with Databricks, including Databricks Academy and community initiatives that offer insight and learning opportunities.
David is a Principal Consultant based out of our Chicago office. He leads high-impact analytics projects for enterprises providing deep expertise implementing cloud-based technologies including Microsoft Azure, Power BI, and more. When he’s not developing data solutions, David closely follows his hometown sports teams– patiently watching and waiting for his Lions to bring their first Super Bowl to Detroit… maybe next year.
In this blog, we outline 5 major steps to a data science project while making the topic of data science more approachable and practical for your organization. Everyone is talking about data science, machine learning, and augmented analytics these days. Organizations are trying to figure out if they need to invest in it, and if…
Do you make business decisions based on spreadsheets or siloed databases with non-standardized structures and formats? Do you see inconsistency in data across business units? Do you have difficulties deciding permissions and access levels to restricted business data? In this blog, we discuss how these problems can be addressed with a data warehouse and provide…
In this blog, we show you how to predict and control customer churn using machine learning in a data visualization tool. Customer churn is important to every for-profit business (and even some non-profits) because of the direct loss of revenue associated with lost customers. To compound that loss, the cost of acquiring a new customer…
For your analytics solution to effectively drive decision making, you need clean data and a flexible data infrastructure that supports all of your current and future analytics needs. Everything you want to do when it comes to analytics – from the advanced stuff, like data science and machine learning, to the basics – hinges on…
In this blog, we provide insight as to why manual data practices can bring unnecessary risk to your projects and how to overcome those obstacles. Why Manual Processes Aren’t “Good Enough” While every analyst knows that automation practices lead to better data quality, more accurate reporting, and ultimately the ability for them to focus on…
To prevent data breaches entirely is very difficult, but following these practices will help minimize risk and vulnerabilities. Increased Data Usage = Increased Risk With the increasing popularity of smartphones, conducting online transactions, and social media, the amount of data that gets collected and stored each day is truly astounding. It is estimated that 2.5…
Data Strategy Session
To thrive with your data, your people, processes, and technology must all be data-focused. This may sound daunting, but we can help you get there. Sign up to meet with one of our analytics experts who will review your data struggles and help map out steps to achieve data-driven decision making.
Fill out this form to get a 30-minute Data Strategy Session with one of our analytics experts.
Contact Us
Have questions? Tell us a little about yourself, and we'll get in touch as soon as we can.