
Last updated on July 17, 2026
The Essential Guide to a Databricks Health Check
By Pat Ross
Ensuring the continuous reliability of your Databricks platform begins with routine health checks. These checks are not merely procedural; they are essential for organizations of all technical proficiencies to uncover and address the subtler, often overlooked issues that compromise efficiency and security. This blog dives into how a thorough Databricks health check can transform your data handling, spotlighting outdated configurations and unseen security vulnerabilities, and identifying the infrastructure pressures that silently degrade your system’s performance.
As your Databricks deployment expands to support more users, workloads, and complex analytics, it becomes increasingly important to periodically audit your clusters, notebooks, jobs, and configurations.
A comprehensive Databricks health check allows you to proactively identify potential issues, inefficiencies, and areas for optimization across your platform. This type of review goes beyond just checking for errors or evaluating recent performance — it takes a holistic look at how your entire Databricks environment is functioning.
In this blog, we discuss:
- What is a Databricks Health Check? ↵
- Risks of Not Performing Regular Health Checks ↵
- Our 6-Step Approach to a Databricks Health Check ↵
What is a Databricks Health Check?
A Databricks health check actively examines and optimizes your data operations by ensuring clusters and jobs are perfectly sized and configured to meet your evolving business requirements.
It also highlights ways to enhance security, maintain best practices, and meet organizational standards. Conducting this vital review annually enables you to preemptively address potential issues, avoid extra costs, and keep your platform in peak condition to support your strategic business and analytics goals.
Risks of Not Performing Regular Databricks Health Checks
Adding Databricks to your tech stack can significantly improve your data engineering and machine learning processes. However, without careful management, the very tools that provide these benefits — such as compute power, notebooks, and orchestration — can introduce unexpected complexity into your system. Some challenges include:
- Ballooning Consumption Costs: Without proper oversight, the cost of Databricks’ compute can escalate rapidly, as different types of workloads and user demands require different compute resources. Regular health checks can address this risk by evaluating and adjusting compute usage, ensuring that your organization selects the most cost-effective options and controls access to prevent unnecessary expenditure.
- Lax Data Governance: The Unity Catalog is a powerful feature of Databricks, but it can be underutilized, leading to passive development and missed opportunities in data governance. Regular health checks actively assess how the Unity Catalog is being used, ensuring that it effectively manages data access, federated searches, and quality controls, helping to improve data governance practices without adding to the tech stack.
- Proliferation of Redundant Code: The ease of starting with Databricks notebooks can result in a sprawl of redundant code, which can lead to potential errors and inconsistencies in ETL processes. A health check can identify areas where code modularization is lacking and recommend strategies to streamline and standardize code across the platform, addressing the risk of inefficiency and errors.
- Inconsistent Practices and Poor Documentation: Databricks interfaces with numerous facets of the data lifecycle, and a lack of uniform best practices and documentation can create security vulnerabilities and inefficient data management. Regular health checks can highlight inconsistencies, verify that best practices are being followed, and ensure that documentation is up to date, thereby reducing the risk of security gaps and operational inefficiencies.
Regular Databricks health checks are a vital part of system maintenance. They enable organizations to preemptively identify and mitigate risks, ensuring that Databricks continues to function as an effective and efficient tool for data engineering and machine learning. By staying ahead of potential issues, teams can maintain a smooth, secure, and cost-effective data operation.
Our 6-Step Approach to a Databricks Health Check
Every Databricks environment is distinct, with its own set of complexities. From projects bustling with hundreds of notebooks and clusters to extensive policies and numerous considerations not immediately evident, the scope can vary significantly.
Despite these variations, our Databricks health check consistently follows a six-step process to ensure thorough analysis and optimization across all environments.
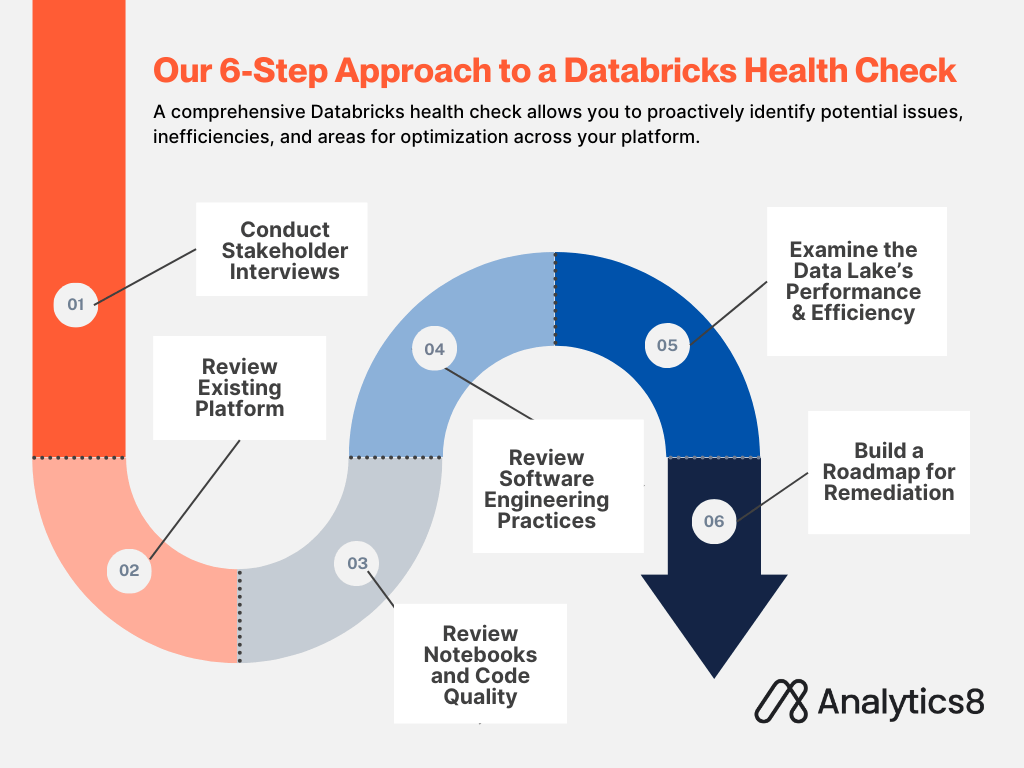
Step 1: Conduct Stakeholder Interviews
Initiate your Databricks health check by interviewing stakeholders to understand the platform’s impact and identify improvement opportunities:
- Interview Databricks developers to gauge their everyday experiences and grasp the condition of the platform and its development environment from those who use it most. Inquire about aspects like:
- Is your creative workflow supported effectively?
- Do you experience productivity fueled by a cluster and/or unity catalog that is well configured?
- How often are you confused by the platform’s data layers, or concerned about causing disruptions in the data flow?
- Engage your data team to pinpoint technical hurdles by exploring the most common sources of frustration. Ask questions such as::
- Which data processes tend to fail the most?
- From which data sources do you encounter the most discrepancies?
- Are there dashboards that consistently prove to be unreliable?
- Consult with the primary users of the data products, such as business executives or leaders, for a wider perspective on the platform’s effectiveness and strategic alignment. This can reveal insights that differ from those of the developers. Consider asking:
- What data do you depend on daily?
- What crucial information seems to be absent?
- How do you rate the reliability and accuracy of the data available to you?
Step 2: Take a Deep Dive into Your Existing Platform
Databricks — catering to the extensive needs of data teams — includes a broad range of capabilities like compute, orchestration, monitoring, and reporting tools. A critical part of this review involves looking at:
- Databricks Unity Catalog: Check setup and configuration. It’s vital to tailor data access within the Unity Catalog to fit the diverse needs of your team. Ask: Is access to data assets properly managed? Ensuring strategic access control is not only a security measure but also boosts user experience. For instance, intentionally granting data access to specific cross-functional teams optimizes workflow and security. This step ensures your Unity Catalog effectively organizes and secures data access.
- Databricks Compute: Navigate through Databricks’ vast compute resources and confirm that ‘personal compute’ usage is a deliberate choice and not just a default action. Ensure your clusters scale dynamically and set them to auto-terminate to save resources. Also, make sure you’re selecting cluster versions mindfully; opting for ‘Long Term Support’ versions can give your production workloads the stability they need.
- Databricks Orchestration: Over recent years, Databricks has significantly boosted its orchestration features. Teams need to assess if they’re making the most of this functionality. Check if your team has enabled notifications for better monitoring, if pipelines are integrated with git repositories for version control, and if you’re utilizing ‘job clusters’ specifically for their intended purpose instead of resorting to ‘all-purpose clusters’ that may not be as efficient.
There is even more to review within your Databricks platform, however, the key components addressed above will help to steer cost efficiency, bolster the credibility of your data, and elevate your data team’s experience.
Step 3: Review Notebooks and Code Quality
Notebooks are at the core of how data teams develop and execute code in Databricks. A thorough review of notebooks is critical to evaluate code quality, consistency, and maintenance requirements across your environment. This step involves:
- Modularity Assessment: Categorize notebooks based on their purpose (e.g. ingestion, transformation, analysis). Look for opportunities to consolidate repetitive code into reusable functions or libraries.
- Code Structure Analysis: Evaluate notebooks for adherence to recommended coding standards. Ensure a consistent structure such as initializing contexts/imports, followed by ETL logic, and ending with data write operations.
- Documentation Review: Check the documentation within notebooks using markdown cells. Ensure there is sufficient explanation of workflow, parameters, and dependencies to help new users understand the purpose and use of each notebook. Additionally, add in error handling and logging where appropriate to supplement documentation.
- Version Control Audit: Confirm notebooks are checked into a code repository (e.g. Git) and follow branch/merge practices. Validate notebooks can be deployed in an automated and repeatable manner.
- Testing Procedures: Assess test coverage for ETL logic and data quality checks within notebooks. One example may be timing functions to identify bottlenecks in your code, which will result in recommendations to strengthen additional testing practices.
Notebooks can provide a collaborative and organized user experience; however, they can also balloon into a ctrl+f nightmare quickly if they are not produced and maintained with intentionality.
Step 4: Review Software Engineering Practices
To maintain a streamlined workflow and ensure code quality, it’s essential that your team actively utilizes remote repository capabilities and native workspace versioning. This approach involves:
- Version Control Practices: Review your version control strategy. Ensure you’re leveraging Databricks remote repository GUI effectively, and that members of the data team are educated on retention policies for code that is not tied to a repository, say in their personal workspace.
- Continuous Integration and Deployment (CI/CD) Processes: Evaluate the robustness of your Continuous Integration and Continuous Deployment (CI/CD) strategies. This includes checking for a coherent release process that incorporates error handling, efficient monitoring, and mechanisms for automatic correction. Assess the team’s understanding of these processes and the use of Databricks CLI and APIs for customized deployment pathways that serve your business needs and enhance reliability.
The goal of this review is to ensure that your data team employs a structured and disciplined approach to code management. This ensures high code quality, smooth production transitions, and robust Databricks platform integrity.
Step 5: Examine the Data Lake’s Performance and Efficiency
A key element of the Databricks platform is its well-known integration with the open source ‘Delta Lake’. Delta tables provide a performant, compliant, and manageable table format to boost the quality of your data assets — in and outside of Databricks. To ensure these benefits translate into tangible improvements without unintended cost increases, review the following:
- Table Optimization: Your data team should evaluate their use of performance boosting techniques like OPTIMIZE, Z-SKPPING, and liquid clustering. These techniques can boost the user experience when running operations on tables. However, it’s important to apply these judiciously, as overuse can lead to higher resource consumption and costs.
- Storage Management: Managing the storage footprint of Delta Tables, which consist of numerous Parquet files and a transaction log, is another critical area. Effective version control enabled by these files can lead to an accumulation of data over time. Implementing a VACUUM policy is essential to remove obsolete files and prevent escalating storage costs.
Failing to leverage Delta Lake’s optimization and clean-up capabilities can result in growing expenses for Databricks and associated cloud resources. This step ensures that your data lake remains cost-effective, well-organized, and high performing.
Step 6: Build a Roadmap for Remediation
Develop a strategic remediation roadmap based on the thorough analysis of your Databricks platform. This roadmap will detail actionable recommendations, set implementation timelines, and assign responsibilities, offering a clear and accountable plan for stakeholders.
- Sort Recommendations: First, sort recommendations into two categories: those critical for a healthy Databricks environment and those beneficial but less urgent. This step prioritizes tasks and streamlines resource management.
- Assign Responsibility and Define Scope: Next, assign a team member to each recommendation to take charge of its implementation, clarifying the scope and impact of each action. This ensures accountability and structured progress.
- Prioritize Implementation: Begin with the most impactful recommendations to address critical issues promptly, then proceed to less urgent tasks. This prioritization ensures timely progress on essential improvements.
- Schedule Training and Learning: Include training sessions for any new features or practices recommended, ensuring the team stays informed and can maximize Databricks’ capabilities.
- Plan Regular Evaluations: Finally, set a schedule for ongoing reviews, preferably every 12 months, to adapt to changes, ensure continued performance, and effectively scale your operations.
Creating this roadmap is a strategic approach to enhancing your Databricks platform, ensuring continuous improvement and alignment with best practices.
Case Study: Optimizing Data Management for a Global Supply Chain Operator
A leading global supply chain operator was struggling with inefficient data processes and high compute costs in their Databricks environment. This hampered their ability to streamline operations and reduce expenses.
We conducted a comprehensive health check of their Databricks environment, focusing on:
- Compute Optimization: We identified overlapping compute demands between pipeline executions and user operations. To address this, we segregated these operations and optimized resource allocation, which significantly reduced costs while maintaining performance. This reduction in compute costs directly saved money, enhancing the sustainability of the financial aspects of Databricks operations.
- Code Centralization: Initially, the code base was decentralized. We centralized the code into modular, reusable functions, reducing redundancy and enhancing code quality. This streamlining of the code and optimization of resources accelerated development and improved query performance.
- Version Control and Updates: We implemented version control and established a routine update process to utilize the latest features. This approach optimized functionality and security, enhancing data governance. Our improved practices and updated platforms facilitated better integration and management of data across different environments.
The health check addressed initial issues and established practices for ongoing improvements. The operator now has a robust, cost-effective data platform to support its global operations and strategic goals.
Talk With a Data Analytics Expert
Key Takeaways
- Regular Databricks health checks are essential to maintaining platform reliability, efficiency, and security.
- These checks help identify and mitigate subtle issues like outdated configurations, security vulnerabilities, and performance bottlenecks.
- Thorough health checks assess clusters, notebooks, jobs, and configurations for optimization opportunities.
- Ignoring routine checks can lead to increased consumption costs and redundant code, thereby affecting data governance and operational efficiency.
- A structured 6-step process ensures a comprehensive review, including stakeholder interviews and platform analysis.
- A health check involves evaluating software engineering practices, from version control to continuous integration and deployment strategies.
- By optimizing Databricks and reviewing data lake performance, teams can prevent unnecessary expenses and enhance platform utility.
- Creating a remediation roadmap with prioritized actions and clear assignments helps sustain ongoing improvements.




![Cloud Migration Strategy Guide [and Checklist]](https://www.analytics8.com/wp-content/uploads/2026/03/Cloud-Migration-Checklist-Thumbnail.png)
