Last updated on October 4, 2024
Guide to Optimize Databricks for Cost and Performance
By Michael Kollman
Databricks offers unmatched flexibility and control, allowing you to tailor solutions to your specific data needs. However, without careful optimization, you risk turning a powerful tool into an unnecessary expense. Learn how to harness Databricks’ capabilities to achieve peak performance and cost-efficiency, ensuring your environment aligns with both performance goals and budget constraints.
Whether optimizing for a new or existing Databricks environment, we’ve identified ways to address performance and cost efficiency, ensuring Databricks remains a valuable investment for your organization. In this blog, we discuss how to:- Manage your resources better with autoscaling ↵
- Track your costs effectively with cluster tagging ↵
- Simplify your optimization with automated tools ↵
- Increase your speed and efficiency with the Photon Engine ↵
- Reduce your latency with disk cache ↵
- Keep your Databricks performance high with continuous optimization ↵
How to Manage your Resources Better with Autoscaling
Autoscaling in Databricks adjusts the number of cluster nodes automatically based on workload demands, ensuring efficient resource use while balancing performance and cost. For example, if a cluster is set to use 1 to 10 nodes, it will start with the minimum and add more as needed, scaling back down during lighter loads. This prevents unnecessary resource use and minimizes costs. To get the most out of autoscaling in Databricks, you need to fine-tune your configuration for your specific workloads. You should:- Set minimum and maximum nodes for your cluster. If clusters are shutting down or failing at maximum capacity, increase the node limit to prevent system overload and ensure stable performance.
- Adjust auto-shutdown settings to balance responsiveness and cost. For cost savings, set the cluster to shut down after a few minutes of inactivity. If faster response times are more important, keep the cluster active longer to avoid the delay of restarting.
- Fine-tune executor settings to improve task execution. Adjust memory, cores per executor, and partition numbers to help tasks run efficiently and improve how well the cluster scales.
- Monitor and adjust autoscaling settings regularly. Use Databricks’ monitoring tools to track cluster performance and adjust settings as workloads change to ensure efficient scaling.
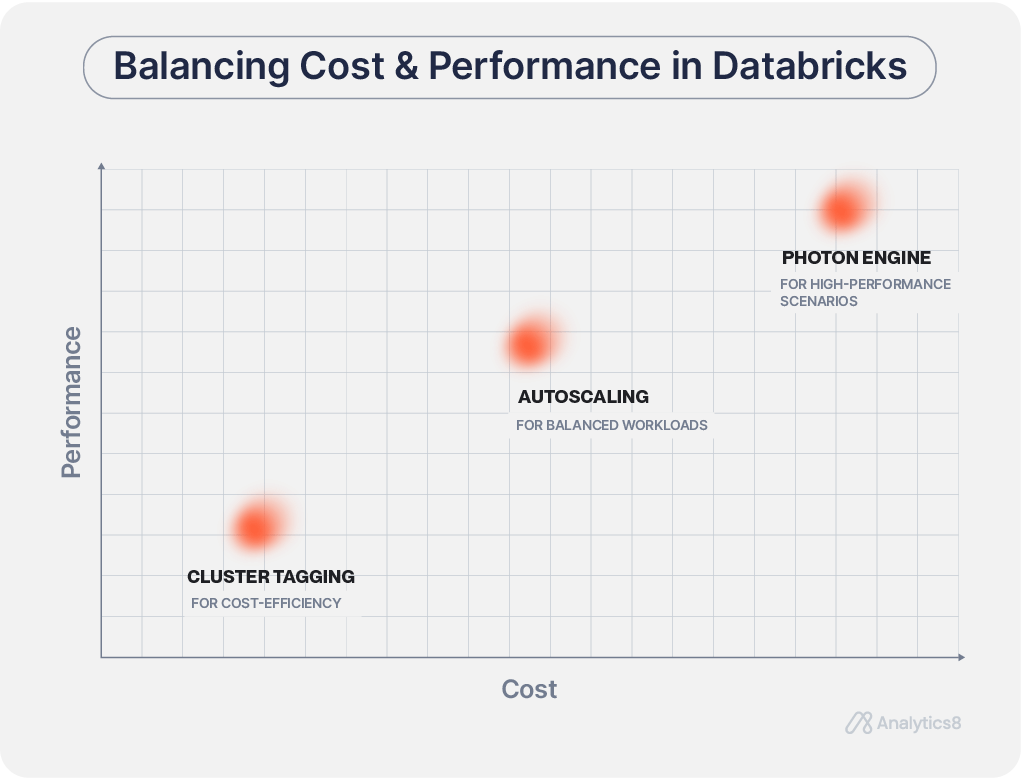
How to Track your Costs Effectively with Cluster Tagging
Cluster tagging in Databricks is a powerful tool for monitoring and managing resources. Apply custom tags to clusters to track resource usage in detail and align data operations with your financial and operational goals. This approach provides the granularity needed for accurate cost tracking and efficient resource allocation. To maximize the benefits of cluster tagging, consider these key aspects:- Develop a strategy that aligns with your organization’s financial and operational objectives. Tag clusters based on the teams using them and the specific workloads they support. This practice helps identify cost drivers and allocate resources efficiently.
- Use tags aligned with your project management needs to monitor resource consumption and ensure spending aligns with your budget and objectives.
- For advanced cost monitoring, leverage Unity Catalog’s “System Tables” to create a wholistic view of how your Databricks compute, storage, workflows, and billing all relate to each other. This allows you to view compute usage and costs by cluster and cluster tags and can be mapped to specific jobs to identify certain jobs which may be resource inefficient providing clear insights into resource allocation.
Achieving true cost-efficiency in Databricks isn’t just about setting up the right features — it’s about consistently monitoring and adjusting them to fit your unique workload patterns. Without this ongoing attention, even the best setup can result in wasted resources. – Matt Flesch, Consultant
How to Simplify your Optimization with Automated Tools
Automated tools in Databricks will streamline your optimization efforts, helping you maintain peak performance with minimal manual intervention. Leverage these easy-to-implement built-in tools to ensure your Databricks environment remains efficient, even as workloads and data complexities grow:- Spark Optimization Hints: Regularly apply optimization hints in your notebooks, like Broadcast Join Hints, data read hints, interval join hints, and disk cache hints. These hints are intended to improve your code so that Spark can execute workloads more efficiently, significantly improving query performance.
- Metrics Tab in Compute Layer: Use the “metrics” tab to monitor your cluster’s real-time performance. This tool profiles your cluster during intensive workloads, helping you identify bottlenecks and optimization opportunities as they occur.
- Unity Catalog’s Data Lineage Feature: Use this feature to consolidate efforts and streamline database management. Tracking data lineage helps you identify inefficiencies and optimize data workflows more easily.
- Delta Lake Table Features: Optimize reads and CRUD operations by configuring Delta Lake’s table features to match your workload needs. These tools enhance data processing efficiency.
- Spark Cluster Logging and Memory Profiling: Automate performance metric collection within your pipelines using Spark Cluster logging and memory profiling. This setup aids real-time analysis and provides insights for long-term optimization.
- Make sure you’re logging and profiling operations in an analytical format. This allows for the creation of an automated cluster profiler, which can be used in tandem with Spark’s cluster logging for a comprehensive optimization system.
- Take your time — automation is powerful, but it requires careful planning and implementation. Avoid rushing the setup process. A well-designed automated system will save time and resources in the long run, but only if it’s built thoughtfully from the start.

Optimization in Databricks is a journey, not a one-time task. As your data needs change, so should your approach to automation and resource management. This is how you maintain peak performance over time. – Michael Kollman, Consultant
How to Increase Speed and Efficiency with the Photon Engine
Photon Engine accelerates queries in Databricks SQL, especially with large datasets and complex workloads. This feature is ideal for high-performance analytical tasks, real-time analytics, and processing large data volumes. Because of its higher cost, it’s best used for large-scale workloads where the need for speed and efficiency justifies the extra expense. Focus on these key metrics to maximize Photon’s performance:- Optimize data types for vectorized execution. Ensure that data types are appropriately chosen to take full advantage of Photon’s vectorized execution capabilities, which improve performance for large-scale analytical queries.
- Leverage Photon for high-performance workloads. Use Photon for large analytical workloads, especially those involving multiple joins, aggregations, or subqueries. Photon is particularly effective for processing and analyzing large datasets with columnar formats like Delta Lake.
- Use Photon for real-time analytics. Photon excels in real-time analytical workloads where low-latency responses are essential, such as interactive dashboards or streaming data.
- Avoid Photon for lightweight workloads. Don’t use Photon for lightweight processing tasks or simple transformations on smaller datasets. In such cases, the added cost may not justify the minimal performance gains.
- Monitor cluster performance and adjust accordingly. Regularly track and adjust cluster settings, such as partitioning and liquid clustering, to ensure you are getting the maximum benefit from Photon for your workload size.
How to Reduce your Latency with Disk Cache
Disk cache is a powerful Databricks feature that reduces latency and optimizes performance. By storing frequently accessed data on disk, disk cache minimizes Spark’s data retrieval time, leading to faster query execution and greater efficiency. To reduce latency with disk cache, ensure your infrastructure can handle caching demands. First, equip the virtual machines running your Spark clusters with solid state drives (SSDs) instead of hard disk drives (HDDs) — SSDs are much faster and essential for quick data access. Also make sure your SSDs have enough capacity to store the necessary cached data, ensuring smooth operations during high workloads. Here are advanced techniques to further enhance disk cache performance:- Enable Delta Caching and use Delta Lake features to improve efficiency. Ensure Delta Caching is turned on and take advantage of Z-Ordering. Regularly run the OPTIMIZE command on Delta tables to compact small files and reduce fragmentation, which improves cache performance.
- Adjust the cache size based on the size of your datasets. Increase the cache size for large datasets or decrease it for small datasets to reduce latency. Use persistent caching to keep frequently accessed data available even after cluster restarts.
- Store data in columnar formats to optimize read performance. Use formats like Parquet or Delta Tables, which are optimized for read efficiency and reduce I/O operations when combined with caching. Properly partition and sort your data to ensure the cache operates on the most relevant subsets.
- Configure clusters with sufficient memory and CPU resources for caching. Ensure your clusters have enough memory and CPU resources to handle the demands of caching. Consider using memory-optimized instances and enable auto-scaling to maintain optimal cache performance during peak workloads.
- Cluster data by frequently queried columns to reduce unnecessary caching. Set up tables to be clustered by lower to medium cardinality columns, such as dates or columns commonly used in filters. This reduces the number of files that need to be searched and cached, improving efficiency.
- Monitor cache performance metrics to fine-tune settings. Track cache hit rates, eviction rates, and other metrics to identify inefficiencies. Analyze logs regularly to adjust cache settings and resolve any bottlenecks in performance.
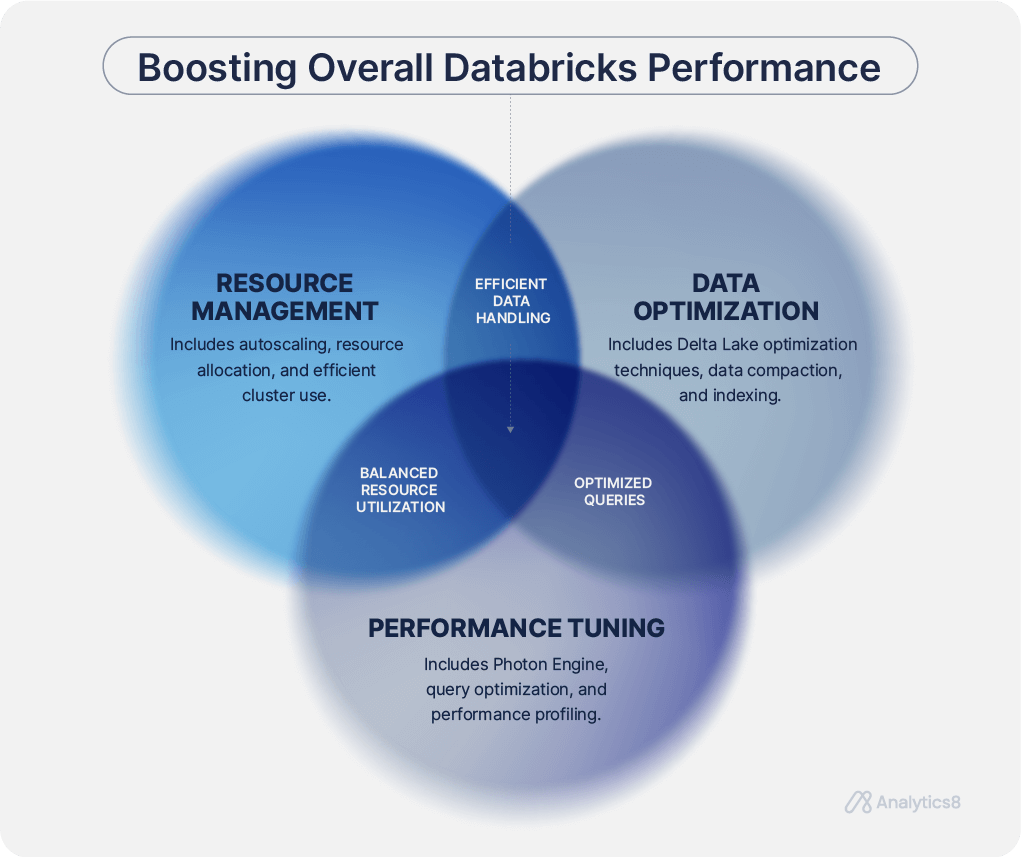
How to Keep your Databricks Performance High with Continuous Optimization
Maintaining high performance in your Databricks environment requires continuous optimization. As workloads evolve and data demands shift, your system must adapt and improve efficiency. Continuously optimize Databricks by following these essential practices and automating where possible:- Regular Code Reviews: Conduct consistent code reviews to maintain optimal performance. Peer reviews, especially through a Pull Request (PR) as part of a CI/CD process, catch inefficiencies and optimize your code before it goes live. This practice also familiarizes the whole team with the codebase, promoting the re-use of modular code across different projects and pipelines.
- Pipeline Logging and Monitoring: Implement pipeline logging to track performance over time. Automated logging helps you identify bottlenecks and inefficiencies within your pipelines, allowing you to make necessary adjustments quickly. Continuous monitoring is crucial for adapting to changing workloads and ensuring your optimization strategies remain effective.
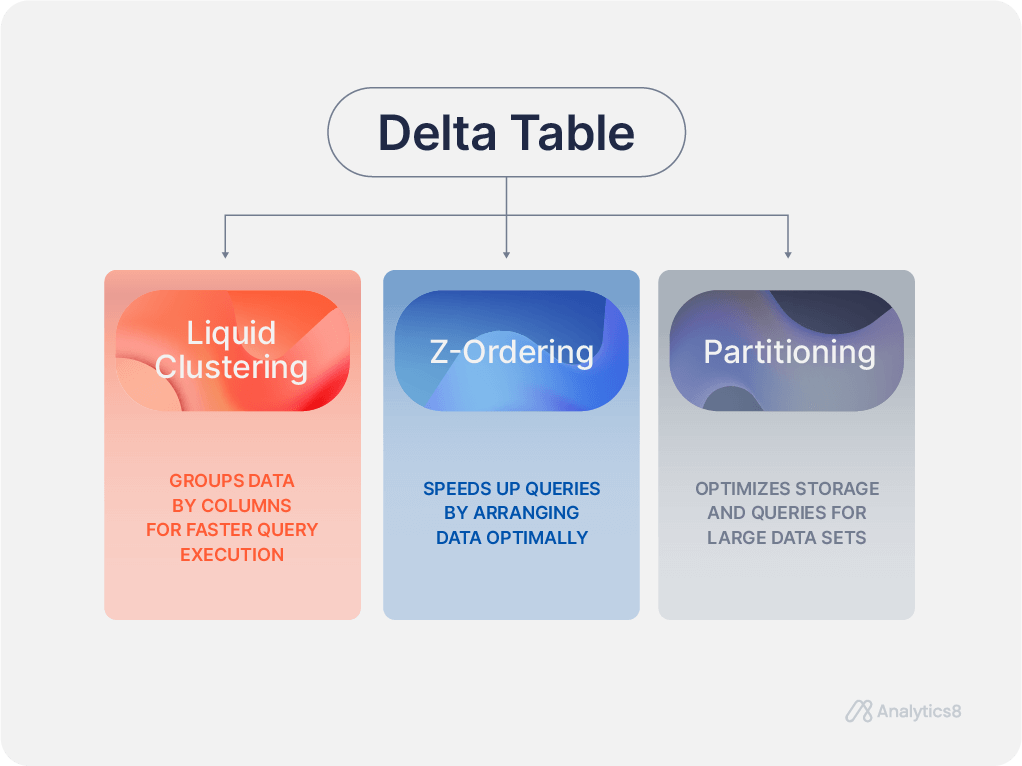
- Data Layout for Delta Tables: Organize Delta tables for optimal performance. Liquid Clustering, Z-Ordering, and Partitioning help speed up read operations. Liquid Clustering is preferred for its flexibility and better performance with evolving schemas. For larger datasets over 1 TB, Partitioning is recommended, with each partition kept around 1 GB for faster access and more efficient queries.
- Optimize and Vacuum Scheduling: If applicable, schedule regular optimization and vacuuming tasks. These tasks maintain peak performance by keeping your data environment clean and efficient. These should be established within a data governance framework/policy to ensure that data retention periods are defined and met.
- Modularize and Optimize Your Code: Breaking your code into modular, performant bundles improves performance and reduces costs. Although Python is traditionally single-threaded, you can employ several techniques to speed up operations:
- Use Async for I/O operations: Apply Async for I/O operations such as network requests, and threading for Spark operations to improve efficiency. For non-intensive or smaller workloads, consider using native Python functions or libraries like Pandas and Polars.
- Test and Monitor Performance: Regularly test and monitor performance in Spark clusters to identify bottlenecks. Building a testing framework for new pipelines allows you to try different techniques and choose the most optimal one. While this may seem labor-intensive, it saves costs by improving efficiency in the long run.
- Choose Third-Party Packages Wisely: Be selective with third-party Python packages. Opt for Python bindings of lower-level languages when possible, as they tend to offer better performance.
- Automate Log Analysis: Set up automated systems to regularly check logs for bottlenecks. When Databricks provides optimization hints, take them seriously — implementing these suggestions can lead to significant performance gains.
Talk With a Data Analytics Expert
Key Takeaways
- Autoscaling in Databricks helps balance performance and cost by dynamically adjusting cluster nodes based on workload
- Cluster tagging enables detailed cost tracking by mapping usage to teams and workloads, improving budget alignment
- Automated tools like Spark optimization hints, Unity Catalog lineage, and Delta Lake features simplify performance tuning
- Photon Engine accelerates query performance for large-scale and real-time analytics workloads in Databricks SQL
- Disk cache reduces latency by storing frequently accessed data locally, improving Spark read performance
- Continuous optimization practices like pipeline logging, data layout tuning, and code modularization improve long-term efficiency
- Regular use of tools like Z-Ordering, liquid clustering, and partitioning boosts Delta table query performance
- Monitoring cache hit rates, autoscaling settings, and optimization hints ensures Databricks environments remain efficient over time