
Last updated on July 26, 2018
A Guide to Data Warehousing: From Strategy to Implementation
By Sean Costello
Do you make business decisions based on spreadsheets or siloed databases with non-standardized structures and formats? Do you see inconsistency in data across business units? Do you have difficulties deciding permissions and access levels to restricted business data? In this blog, we discuss how these problems can be addressed with a data warehouse and provide a complete guide to data warehousing including a breakdown of the different types of data warehouses, how to decide if you need one, data warehouse alternatives, and easy steps to ensure a successful data warehouse implementation.
In this blog, we cover:- What is a Data Warehouse↵
- What are the Benefits of a Data Warehouse↵
- Common Types of Data Warehouses↵
- What are Key Differences Between OLTP and Data Warehouse (OLAP) Systems?↵
- Where are Data Warehouses Stored?↵
- What Does a Typical Data Warehouse Implementation Look Like?↵
- 3 Questions to Ask and Answer if Considering a Data Warehouse↵
- Alternatives to a Data Warehouse (If A Data Warehouse is Not Right for Your Organization)↵
- 7 Steps to Achieve Success with Your Data Warehouse Project↵
What is a Data Warehouse?
Businesses have applications that process and store thousands, even millions of transactions each day. The ability to create, retrieve, update, and delete this data is made possible by databases, also referred to as online transaction processing systems (OLTP). While these databases have traditionally been “relational” (SQL Server, Oracle, MySQL, DB2 etc.), in recent times, “non-relational databases” (Cassandra, MongoDB, Redis etc.) or files systems (like Hadoop) have been adopted as an alternative for storing raw data.A data warehouse, also commonly known as an online analytical processing system (OLAP), is a repository of data that is extracted, loaded, and transformed (ELT) from one or more operational source system and modeled to enable data analysis and reporting in your business intelligence (BI) tools.
What are the Benefits of a Data Warehouse?
Data warehouses will help you make better, more informed decisions for many reasons, including:- Improved business intelligence: When you integrate multiple sources, you make decisions based on ALL your data.
- Timely access to data: Quickly access critical data in one centralized location.
- Enhanced data quality and consistency: Data throughout the organization is standardized and stored in the same format so all departments are making decisions based on uniform data.
- Historical intelligence: Because a data warehouse stores large amounts of historical data, you can identify trends through year-over-year and month-over-month analysis.
- Quick query response times: Most data warehouses are modeled, built, and optimized for read access, and that means fast report generation.
- Data mining: Explore “Big Data” to predict future trends.
- Security: A data warehouse makes role-based access control (RBAC) easy by giving access to specific data to qualified end users while excluding others.
- Auditing: Data stored appropriately in a data warehouse provides a complete audit trail of exactly when data was loaded and from which data sources.
- Analytical tool support: Analytical tools that offer drill-down ability work best when extracting data from a data warehouse.
- Government regulation requirements: With a data warehouse, it is easier to comply with Sarbanes-Oxley and other related regulations than with some transactional systems.
- Metadata creation: Descriptions of the data can be stored in the data warehouse so that users understand the data in the warehouse, making report creation much simpler.
- Scalability: Modern cloud MPP databases offer the ability to scale compute and storage on the fly without the need to manually provision resources.
- Real-time performance: A data warehouse can merge disparate data sources with capabilities to preserve history as soon as the data is available.
- Centralized business logic: Storing business logic in the data warehouse minimizes the chances of having multiple versions of the truth.
Common Types of Data Warehouses
There are many types of data warehouses, but these are the three most common:- Enterprise data warehouse: Provides a central repository tailored for support decision-making for the entire enterprise.
- Operational Data Store: Similar to the enterprise data warehouse in terms of scope, but data is refreshed in near real time and can be used for operational reporting.
- Data Mart: This is a subset of a data warehouse used to support a specific region, business unit, or function area (i.e., Sales).
What are Key Differences Between OLTP and Data Warehouse (OLAP) Systems?
The data stored in data warehouses and data marts (OLAP) is de-normalized, which allows easy aggregation, summarization, and data drill-down. Second, data warehouses enable business users to gain insights into what happened, why it happened, what will happen, and what to do about it. On the other hand, OLTP systems are single applications built to quickly record specific business processes, like credit card transactions. Also, unlike the de-normalized nature of data warehouses, the data structure for OLTP systems is highly normalized to facilitate data atomicity, consistency isolation, and durability. Due to the complexity in writing queries for analysis in such applications, developers or subject matter experts are most often required for support. Relational database technologies are generally optimized for OLTP or OLAP use cases. For example, Microsoft SQL Server and Postgres are row-store databases that are optimized for OLTP. Cloud-based MPP (massively parallel processing) databases such as Snowflake and Google BigQuery are column stores that are optimized for OLAP. It should be noted that while OLTP databases can be used for data warehousing use cases at smaller data volumes, OLAP databases are typically not suitable for transactional use cases.Where are Data Warehouses Stored?
Since data volumes are growing exponentially, a data warehouse becomes critical, and considerations should be made on the hardware that stores, processes, and provides a medium for data movement. Data warehouses can be stored on-premise, in the cloud, or a mixture of the two environments. Your decision may depend on requirements to keep organization-mission-critical applications on-premises. If you are looking into cloud solutions, take into consideration industrial regulations, security, visibility, accessibility, latency, and trustworthiness of the cloud providers. (Some top cloud providers include Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.)
What Does a Typical Data Warehouse Implementation Look Like?
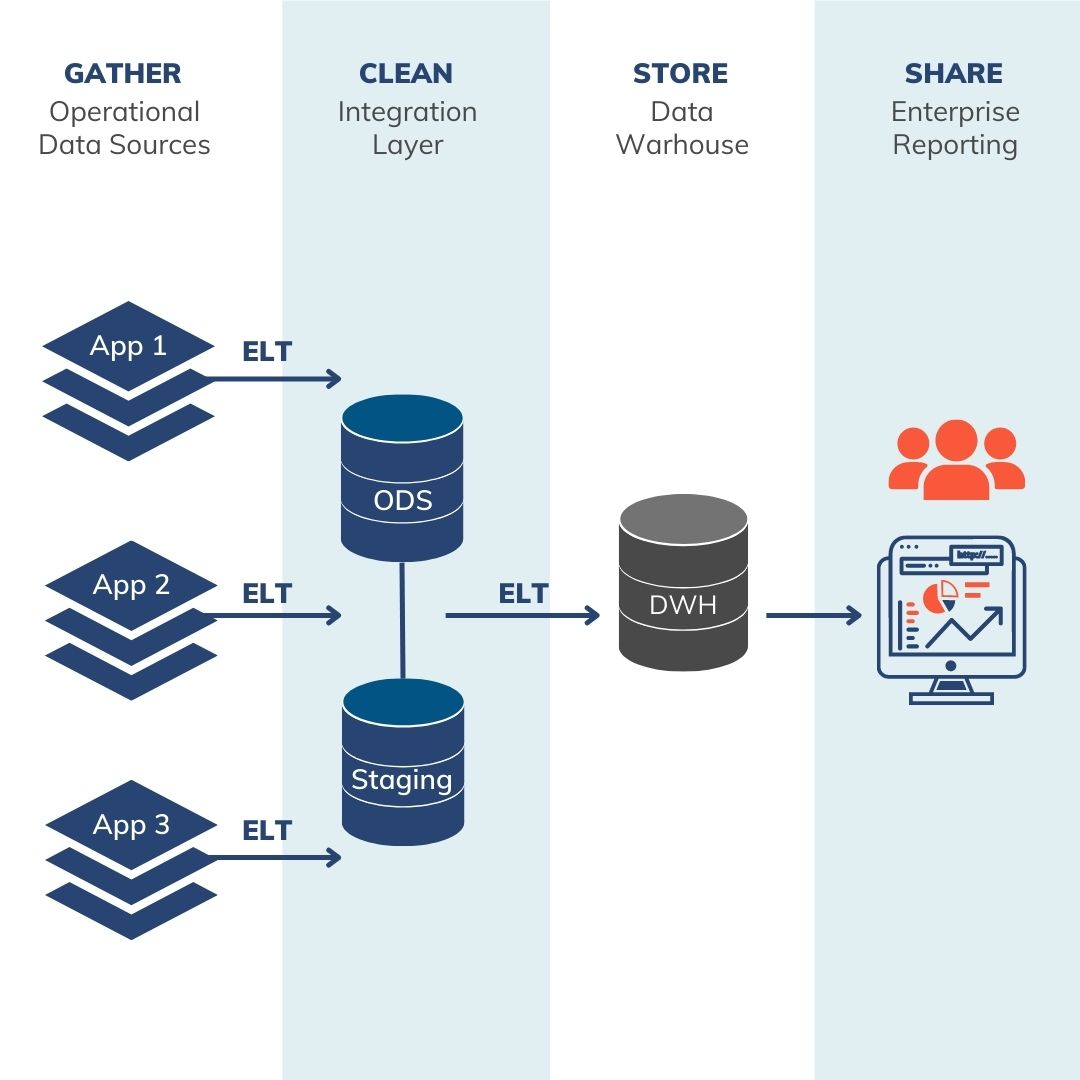
Gather Layer in a Data Warehouse
The gather layer consists of various data silos—these can include ERP systems, CRM, Excel spreadsheets, even Access databases housing corporate or divisional data. The storage subsystems used by these applications are typically not structured for easy querying or navigation (if direct access is available at all). Native reporting may be possible in some of these applications; however, functionality is typically very sparse, and reporting is limited to only the data within a single system.Clean Layer in a Data Warehouse
The clean layer applies business logic and other calculations to data that is ultimately going to be made available in the store layer (or data warehouse). Business logic can include custom KPI’s, business-specific calculations or rulesets, data hierarchies, or new derived columns that otherwise are not available from any source system. Data typically only temporarily exists in the clean layer—this layer exists only to create these custom values and pass through to the data warehouse, and end user reporting or querying against the clean layer is not allowed.Store Layer in a Data Warehouse
The store layer represents the denormalized data warehouse that is described further throughout this blog post. While there are several design models, the Kimball approach is a leading design through which information is organized into dimension and fact tables and joined in star schemas for ease of use. The store layer may contain data marts on top of the Kimball star schemas that are optimized for specific downstream use cases.Share Layer in a Data Warehouse
The share layer isn’t a formal layer as much as a representation of all the various ways data—which resides in the data warehouse—can be consumed. These uses include querying via a BI tool, direct SQL querying, or even automated extracts to feed other, unrelated systems (reverse ETL).3 Questions to Ask and Answer if Considering a Data Warehouse
Take a closer look at how information is stored and shared across your enterprise. Inconsistencies in data and reporting, difficulty sharing data, and multiple data sources are all signs that a data warehouse might be the business solution for you. Here are three basic questions to ask and answer if you are still considering: 1.) Do you store data in various source systems? Gathering data that is structurally different from operational databases, flat files, and legacy systems can be challenging for many organizations. How can you integrate data from disparate systems with different structures? Sometimes it’s done by spending days and weeks pulling data to create reports. Also, operational systems are not modeled for analytical queries, and most often contain data specific to a business area. The lack of data integration across multiple business areas might not give a full picture of the health of an organization. In addition, a lack of human capital with the relevant or advanced skills and permissions to query data applications can be an impediment when dealing with various source systems. A data warehouse can make this process efficient and automatic by extracting, loading, and transforming (ELT) data from various source systems in a standardized and consistent manner. The ability to access such data from a central location not only allows users to make quick and better business decisions, but also saves time that would’ve been wasted trying to retrieve and blend data from multiple information systems. 2.) Are you experiencing performance issues by reporting against operational systems? Operating systems have volatile data that changes often. Consequently, running reports directly against such systems with almost real-time data can cause performance problems, and insights gathered might be inconsistent. A data warehouse can solve this problem because they are usually optimized for read access, resulting in faster report generation. 3.) Do you have a single source of the truth? Reporting on data that is stored and formatted differently across siloed enterprise information systems results in inconsistency across departments. Well-built data warehouses improve data quality by cleaning up data as it is imported, thus providing more accurate data. This means that one version of the truth can be provided for every department across the enterprise, providing consistency and assurance that each department is using the same data. [cta_callout modal_id=”15678″] Talk to an expert about your data warehouse needs. [/cta_callout]Alternatives to a Data Warehouse (If A Data Warehouse is Not Right for Your Organization)
Sometimes, data warehouses cannot solve all business problems due to their inherent dependence on relational data structures. The adoption of new data sources, such as social media, IoT, logs, video, and audio, has resulted in rapid changes in both content and volume. The downside of this has been the lack of internal checkpoints of data ownership, which makes it difficult to apply data governance principles accustomed to traditional data warehouse projects. As an alternative to the challenges brought about by the new ways of storing data, organizations have adopted emerging technologies such as data lakes, data lakehouses, data visualization, non-relational databases, and perhaps polyglot persistence. Let’s have a look at what they offer:Data Lakes
A data lake is a collection of unstructured, semi-structured, and structured data, copied from one or more source systems (technology-independent). The data stored is an exact replica of the source. The goal is to make the raw data consumable by highly skilled analysts within an enterprise for future needs that are not known at the time of data capture. The key difference in comparison to the data warehouse or data mart is that the data is not modeled to a predetermined schema of facts and dimensions. It is the lack of structure that empowers developers, data analysts, or data scientists to create exploratory models, queries, and applications that can be refined endlessly on the fly. Here are three characteristics of data lakes:- All data is extracted and loaded from the source system.
- All data types are supported.
- Data transformation and modeling are done to meet analysis requirements.
Read: “The difference between a data lake vs a data warehouse“
Data Lakehouse
A data lakehouse combines elements of both a data lake and a data warehouse within a single platform. Like a data lake, lakehouses store structured, semi-structured, and unstructured data as objects in low-cost storage. Using a metadata layer, data lakehouses contain features typically found in RDBMS (relational database management systems) such as ACID transactions, schema enforcement, indexing and caching, time travel, and access control. Data lakehouses can be accessed through traditional BI tools and APIs. Databricks is a leader in the data lakehouse space, while there are up-and-coming contenders like Dremio. Snowflake also offers features that function similarly to a data lakehouse.Self-Service BI
Self-service BI is an approach that gives freedom and responsibility to business users to create reports without relying on IT. Sometimes data warehouses lack the agility to scale to meet the needs of quickly evolving companies. Self-service solutions allow companies to be nimble by giving departments access to data and information on demand. All skill levels can typically use these types of solutions:- Casual users: Possesses a limited BI skillset and requires simple requirements.
- Power users: Skilled BI users with the ability to analyze data and create new reports and dashboards from scratch.
- Business analysts: Advanced BI skills in data exploration, modeling, and deployment of BI environments.
No-Relational (No SQL)
NoSQL is an architectural design approach to databases that does not rely on the traditional representation of data. Relational database management systems organize data in tables, columns, rows, or schemas for CRUD (create, read, update, and delete) operations. In comparison, NoSQL databases do not rely on relational structures, but on more flexible data models that offer speed, scalability, and flexibility. These are key characteristics needed to deal with “Big Data”. There are various types of NoSQL databases available on the market today, and they fall into four main categories:- Key-value databases: These databases use associations between elements as a data model such that a key is associated with only one value in a collection. Usually, the value stored is a blob. This means that no one knows what the value of the data is until a key is provided as an identifier to provide access. Key-value database offerings include DynamoDB, Azure Table Storage, Riak, and Redis.
- Document databases: They store and retrieve documents in several formats, such as XML, JSON, and BSON. Popular providers of document stores are Elastic, MongoDB, CouchDB, Terrastore, RavenDB, and Azure DocumentDB.
- Wide-column databases: These databases store data in tables with rows and columns much like traditional relational databases. However, the names and formats of columns can vary from row to row across the table. In other words, columns of related data are grouped together, enabling the retrieval of related data in a single query operation. On the other hand, relational databases store rows in different places on disk, which would require multiple disk I/O for data retrieval. Providers for such databases include Hadoop, Cloudera, Cassandra, HBase, Amazon DynamoDB, and Hypertable.
- Graph databases: These databases utilize graph structures to store, map, and query relationships between entities. Providers for such databases include Sparksee, InfiniteGraph, New4J, and OrientDB.
7 Steps to Achieve Success with Your Data Warehouse Project
If you have settled on implementing a data warehouse, here are some things to consider for a successful project: 1.) Start with skills. One of the key reasons a data warehouse projects go awry is talent deficit. A data warehouse project requires experienced project members, so be sure to assess the skills of your team. Are they skilled in data integration and modeling? Are they trained on new technologies and approaches? Have they worked on similar projects, both in domain and scale? Do you have team leads who are capable of mentoring and guiding less skilled staff?- Do assess skills related to requirements, architecture and design, delivery, testing, and project management related to data warehousing. Partner with consultancies when necessary to fill skills gaps and provide a co-development model in which your internal team is “taught to fish”.
- Don’t omit critical project roles or stretch current staff outside of their areas of expertise due to a lack of resources.
Read: “How to Build an Effective Data Analytics Team.”
2.) Identify business requirements with corporate and departmental objectives in mind. At this stage, it is not about the data; it’s about identifying business needs to operate more efficiently and make data-driven decisions. Another reason data warehouse projects fail is that requirements do not address the business objectives; instead, they are created to demonstrate progress and complexity of the project.- Do address all of your reporting and analytic gaps as a priority. What new capabilities can we enable? What are the “expensive” business questions that can’t be asked of your current data and systems? What, in a perfect world, should be measured (regardless of what is currently available)?
- Don’t just port all your existing reporting requirements to the new platform.
Read: Why Now is the Time to “Update Your Data Strategy” and How to Do It
3.) Assess data requirements. With analytics requirements in hand, identify the sources of data needed to achieve each requirement. Asses the quality of the data sources available and identify any data remediation that may be required for each source. Compile a data warehouse Bus Matrix and conceptual data model—both will become core elements of your data warehouse requirements.- Do leverage Data Discovery to validate and assess data assumptions.
- Don’t waste time on data for fringe use cases or low-priority analytics (which is easy to do!).
- Do leverage the Bus Matrix as a tool to communicate and gain consensus on completeness and prioritization. Find a quick win or two to begin with, set the stage for further expansion, and gain momentum from there.
- Don’t be too aggressive with the scope. Creating momentum and success early creates opportunity in later phases.
- Do get an outside opinion. Data warehouse experts will expedite project completion and accuracy. Conduct a “bake off” to compare various tools (database platform, integration, and business intelligence/reporting) using a subset of your own data.
- Don’t select a tech stack because it’s the newest, coolest technology.
- Do: Define clear success criteria for each phase and inspect to completion to ensure that you are not reporting false velocity.
- Don’t: Dramatically change scope during a sprint or phase. Some change is normal and expected, but too much change will jeopardize the phase and create the risk of running over budget and behind schedule.
- Do measure value in dollars, time saved, insights gained, and the value of those new insights.
- Don’t focus on tasks completed; focus on the business value instead.
Talk With a Data Analytics Expert
Key Takeaways
- A data warehouse is purpose-built for analytics, storing structured data from multiple sources to support reporting and decision-making.
- Unlike transactional systems, data warehouses are optimized for querying and analysis, with a focus on historical trends and performance.
- Modern warehouses often run in the cloud, offering scalability, flexibility, and cost-efficiency over on-premise solutions.
- Implementation involves multiple layers, including data ingestion, cleansing, transformation, storage, and access via BI tools.
- Organizations should assess whether data is siloed, inconsistent, or difficult to access to determine readiness for a data warehouse.
- Alternatives like data lakes and lakehouses may be appropriate depending on the type, structure, and use cases of the data involved.
- Successful data warehouse projects rely on clear business goals, the right team, and a phased, outcome-driven roadmap.


![Cloud Migration Strategy Guide [and Checklist]](https://www.analytics8.com/wp-content/uploads/2026/03/Cloud-Migration-Checklist-Thumbnail.png)


