
Last updated on May 8, 2026
Databricks and dbt Partnership: What It Means for Your Data Engineering Pipeline
By Simon Collis
Databricks and dbt have recently joined forces, and in this blog we provide an overview of each tool, what synergies exist from this partnership and what it means for your data engineering pipeline, and how you can get started with using the tools together today.
Is collaboration across your data teams difficult? Is data drifting an issue for your organization? Are you looking for a solution that will allow your entire data team to work in a single platform—whether it be to transform your data or to build, test, and deploy code?
The Databricks and dbt partnership provides the solution you need to bring your analytics team and their tooling to the same platform trusted by their data science and data engineering counterparts. Each tool is unique on its own, but together, they help to simplify your modern data stack.
Databricks: A Cloud-Based Data Engineering and Machine Learning Platform
If you haven’t heard of Databricks by now, you are missing out. Databricks is an end-to-end, unified data platform that stores, transforms, and even displays data. It implements a data lakehouse architecture, which bridges the gap between a data lake (think large amounts of data in any format—structured or unstructured) and a data warehouse (highly governed, curated data optimized for reporting).
Databricks is unique in that it allows for the entire data lifecycle to exist within one ecosystem, which differs from competitors that often require multiple platforms and tools when building out a data pipeline.
What are Databrick’s Strengths?
Databricks is one of the most widely used advanced analytics platforms in the world. It not only serves to bridge the gap between a data warehouse and a data lake, but Databricks also is:
What are Databrick’s Limitations?
Despite its many strengths, data transformation is one area where clients have struggled using Databricks. The platform provides myriad ways to transform data, which is great in terms of flexibility, but it means development teams need to have a clear, defined framework in place, which can take precious time and resources to implement properly.
DBT (Data Build Tool): A Transformation Framework for Your Data Pipelines
In the relatively new era of the modern cloud data warehouse, dbt was one of the first tools in the market to micro-focus on transforming data. Thus, DBT rose in popularity as tools like Redshift, BigQuery, and Snowflake emerged as market leaders for data management in the cloud. DBT gives a structured approach for teams to develop like engineers by leveraging git (source and version control) and writing SQL for transformations on top of a data warehouse.
Significant reasons DBT gained so much popularity recently are that it embraces data democratization, writing transformations in SQL, and the value of the open-source project. Every cloud data warehouse uses SQL, which data analysts and data engineers mutually understand. This opened possibilities for teams to work in tandem, while allowing a full community to help drive product development and innovation.
What are (Data Build Tool) dbt’s Strengths?
The DBT framework makes it simpler to develop, test, document, and deploy your transformations in the cloud while applying proven engineering best practices and workflows. Data teams using dbt find unmatched collaboration, time to value, and a cohesive understanding of the data warehouse throughout an organization. Some specific advantages of DBT Cloud to highlight are the Version Control Integration, the centralized documentation hub, the jobs, and its testing capabilities.
Git Integration
Within dbt Cloud, it gives anyone without version control experience a guided process to create branches, commit development work, and open pull requests. This is critical for many organizations to enforce version control best practices.
Centralized Documentation
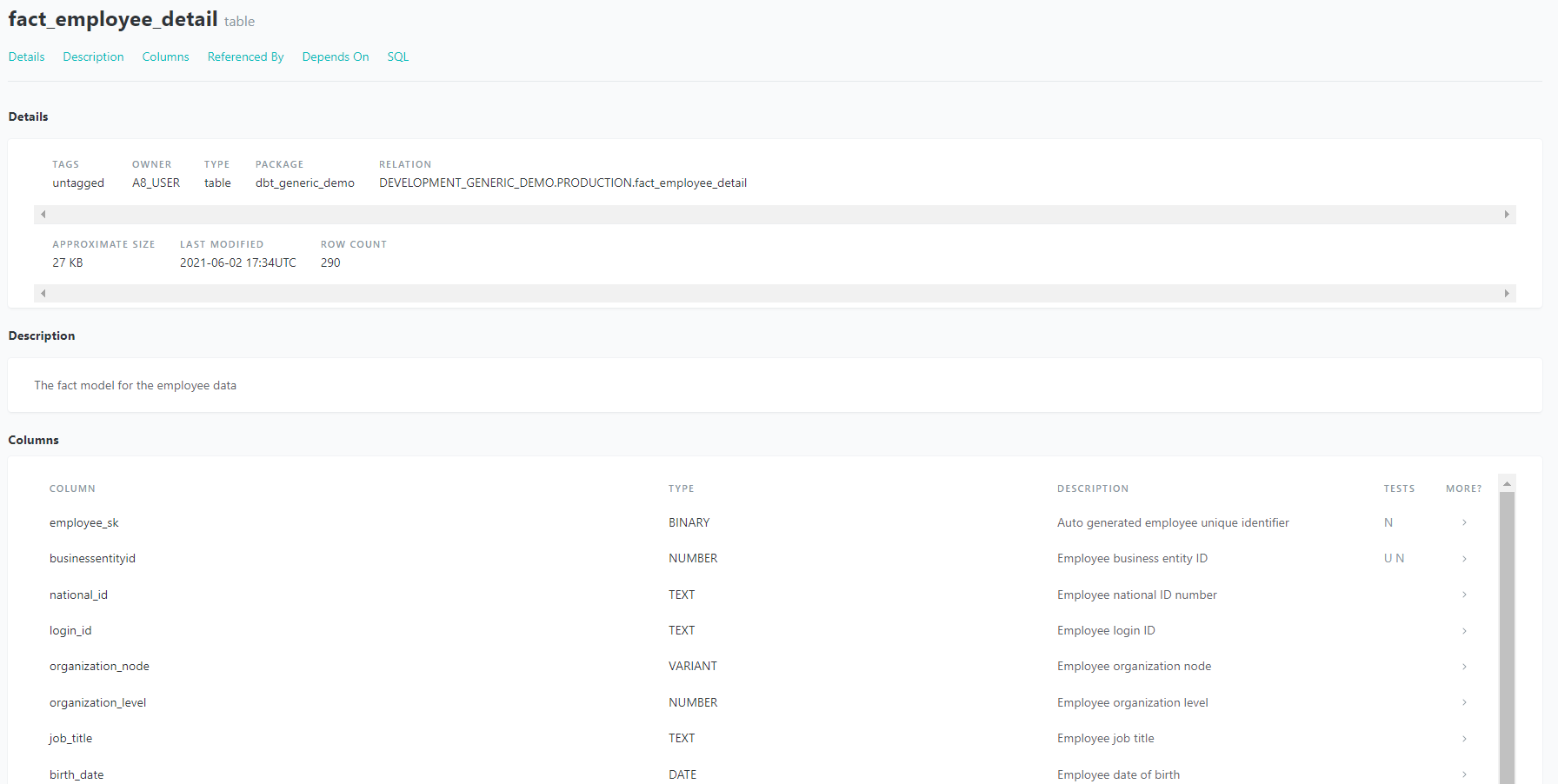
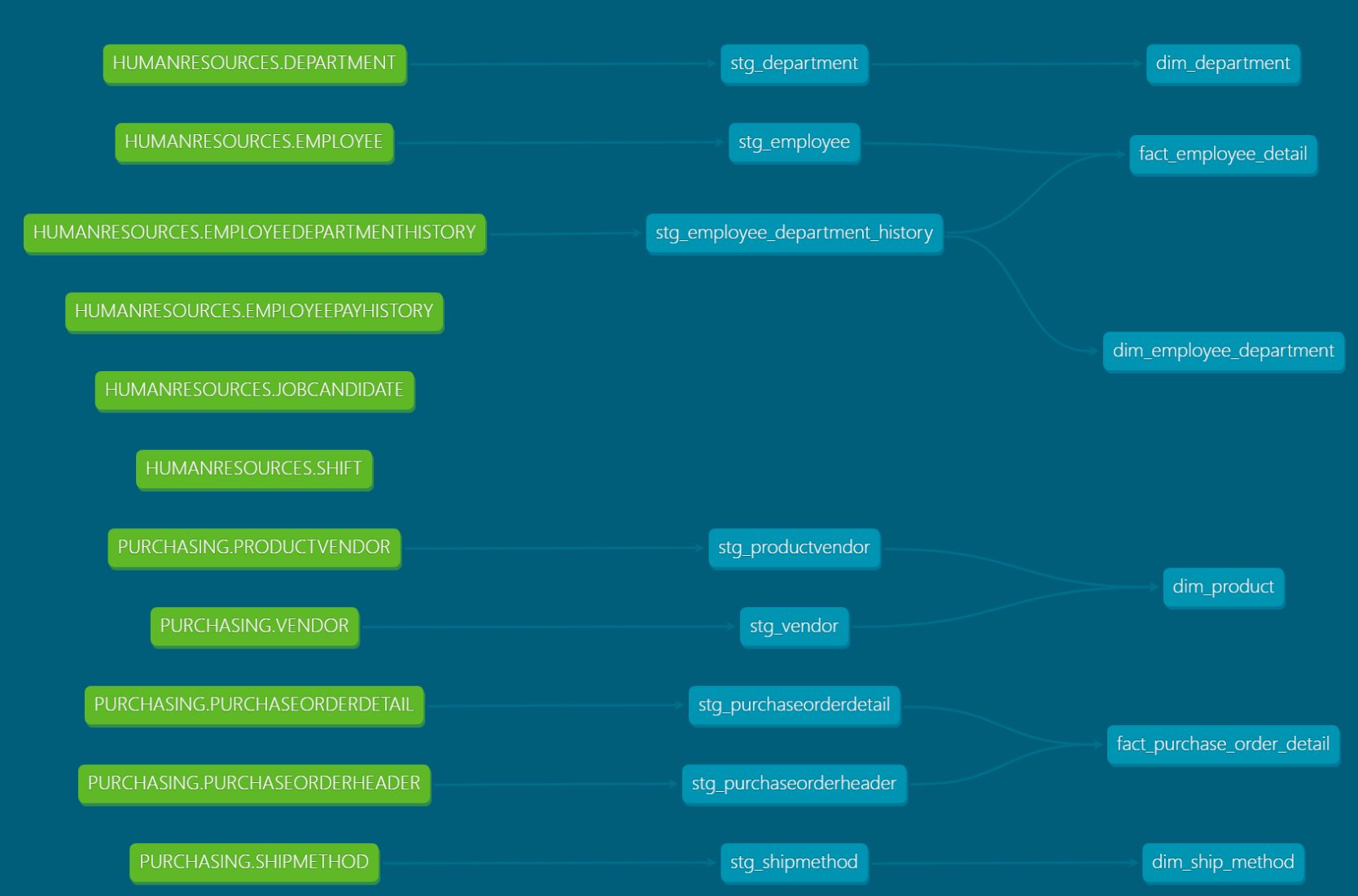
DBT offers a centralized documentation hub for definitions and metadata on all your fields within tables/views. By simply writing down definitions in YAML files, you can have an entire data warehouse documented in one spot. Additionally, dbt automatically tracks lineage for models, which is extremely beneficial for understanding the flow of your environment.
Jobs
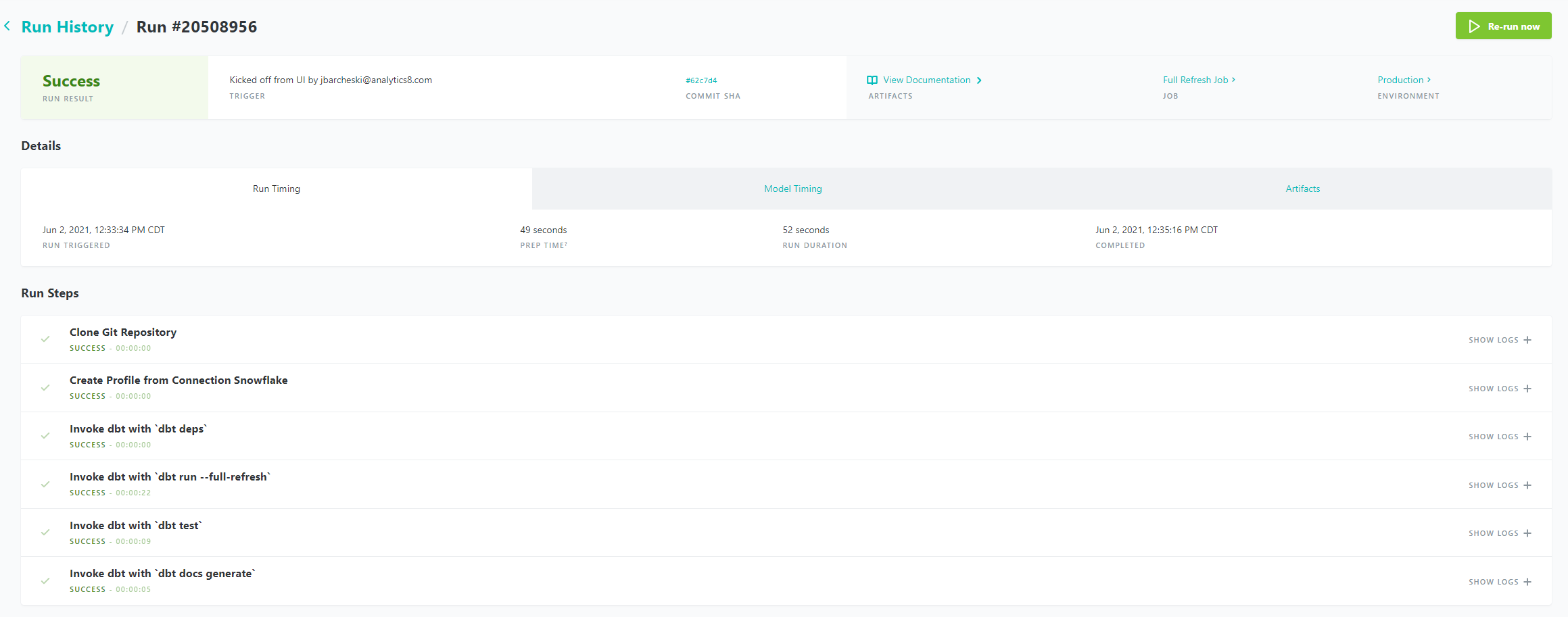
DBT Cloud makes it simple to orchestrate your environment. DBT has excellent CI/CD and production scheduling abilities for your pipelines. This has saved teams numerous hours of development and maintenance work on their pipelines.
Testing
DBT comes out of the box with advanced testing capabilities. There are two primary types of tests in DBT—schema tests and data tests. Schema tests are used many times to catch common errors like nulls, grain, referential integrity, etc. You can use some of DBT’s predefined tests or even write your own. On the other hand, you can also write data tests that apply to a single table, which can be beneficial to track specific use cases. This functionality has proven essential to organizations to uncover problems early.
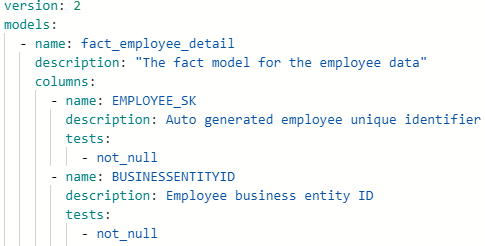
These are just a few of the many impressive features of dbt. This makes transforming your data a simple process.
What are (Data Build Tool) dbt’s Limitations?
The typical cloud data warehouses that dbt operates on top of have been Redshift, BigQuery, and Snowflake. Those platforms are typically used to solve business intelligence (BI) problems, which means that data engineers and data analysts have collaborated, while other teams have separately attacked problems that a data lake could solve. Thus, data science teams, for example, have often been siloed from the data analytics teams in many organizations.
Recently, Databricks has impressively accelerated its SQL capabilities and evolved the data lakehouse concept, offering a unique opportunity to further unite data teams at an entirely new level.
Only a few years ago, it was difficult to imagine a world where an entire data team could use a single platform to query both their data warehouse and data lake. dbt and Databricks have made this an achievable reality.
Databricks and dbt Partnership: Welcoming Analytics Engineers to the Data Lakehouse
Databricks and dbt have partnered to simplify the data lakehouse. Although Databricks is a fantastic platform for data teams to get the most out of their data, it can be cumbersome to use without a defined framework for building, testing, and deploying code. The solution here is to use dbt on top of Databricks.
From a high-level architectural perspective, dbt works on top of Databricks once the raw data has already been loaded into the Delta Lake. From there, developers write their code within a dbt environment; however, the code is pushed down and executed using the compute from Databricks and Apache Spark. It’s important to note that the data is not stored or processed by dbt; everything is contained within the Databricks environment.
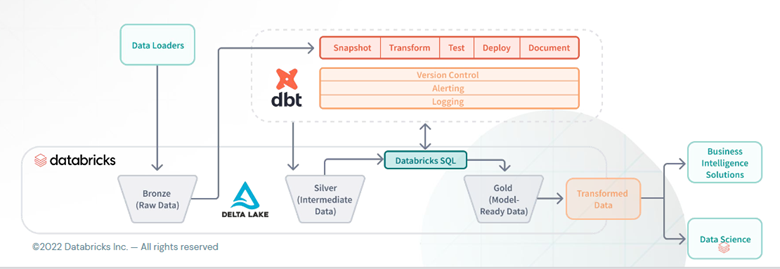
Learn What DBT Can Bring to Databricks
The Combined Strengths of a Databricks and dbt Partnership
The new partnership between Databricks and dbt is an exciting prospect for companies that are currently using Databricks without any sort of development framework, and even for companies that may be using dbt with another platform but are considering a switch to Databricks. Here are examples of why:
Talk to an expert about your DBT or Databricks needs.
How to Get Started with Databricks and dbt to Enable Analytics Engineering
Now that we’ve convinced you that a partnership between Databricks and dbt is a good thing, let’s talk about how you can dive in and get started.
Step 1: Determine if Databricks + dbt is the right fit for you.
Before jumping right in and screaming “take my money, Databricks and dbt!”, it’s first worth asking if it even makes sense for your business. While we think this is a great combination, you should consider a few questions before jumping in headfirst:
- Do you already have an existing Databricks environment?
- Is your data engineering team skilled with, or prefer using SQL?
- Does your team struggle with rapid deployment, documentation, and/or quality control?
- Does your team already utilize dbt with another platform, and are you looking to migrate to a new one?
If you’ve answered yes to any of these questions, then adding dbt to your current stack could be a great investment! If, however, you find yourself in the following situations, then it could be worth reconsidering:
Step 2: Understand the ins and outs of both Databricks and dbt.
If you are interested in learning more about Databricks or dbt and getting hands-on experience, there are several resources available to you.



![Cloud Migration Strategy Guide [and Checklist]](https://www.analytics8.com/wp-content/uploads/2026/03/Cloud-Migration-Checklist-Thumbnail.png)

