Data Integration Tools & Techniques: Understanding the What, Why, and How
By Sean Costello
In this blog, we discuss what data integration is, why it’s beneficial, the different approaches you can take and tools you can use, as well as best practices to implementing a data integration solution.
If you aren’t embracing data-driven decision-making and using your data as a strategic asset, you’re going to be left behind. But how do you ensure that your organization’s data is accessible—and actionable—across the entire organization? It starts with data integration.
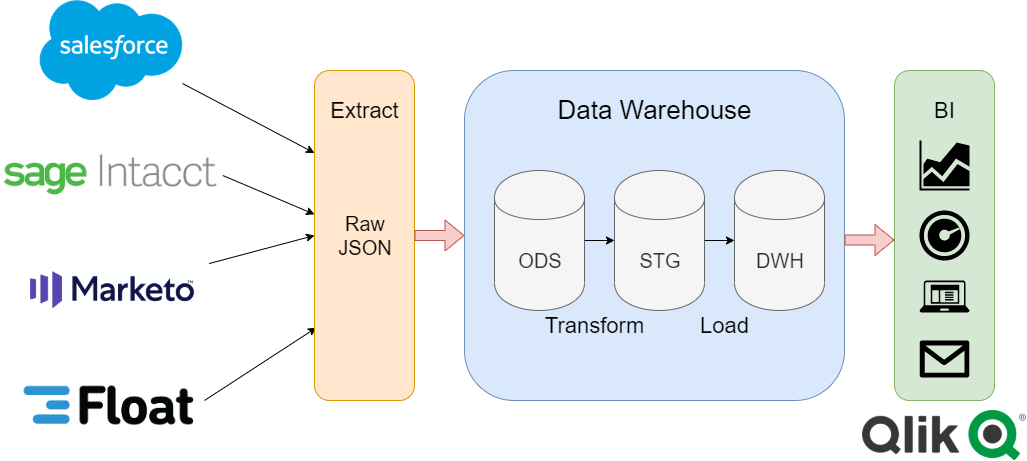
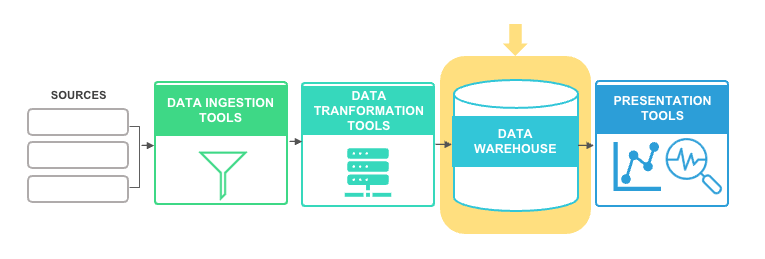
Example of CRM, GL, marketing, and scheduling data integrated into a data warehouse with a business intelligence tool as a user interface.
What is Data Integration and Why is it Important for Business Analytics?
Data integration is the process of connecting disparate data of differing formats for unified analysis.
As organizations continue to collect more data, they likely have multiple data sources that they use in isolation for a variety of different reasons. But siloed data can pose challenges—data quality issues, information out of context, duplicate efforts that waste valuable time and resources, etc., making it difficult for a business to maximize the value of their data.
Breaking down data silos allows business users to add context and perspective to data which makes it much more valuable.
When done well, data integration enables your organization to meet business demands, save time and money, reduce errors, increase data quality, and deliver more valuable data to your business users, who in turn can shift their focus to provide valuable analysis.
What is the Best Approach to A Data Integration Solution?
Every organization is going to have unique data integration needs because they each have varying business needs.
The right approach to data integration for you helps answer the questions “who, what, where, how, and why” so that your business users translate the data into something more meaningful and actionable.
Depending on where you expect your users to access data, here are a couple of approaches you can take with a data integration solution:
Persistent staging layer/base layer: You can integrate your data into a centralized location such as a data lake or a persistent staging layer in a data warehouse. The benefits of using a data lake for data integration is that you can replicate your data as-is and store it in one place for ease of access and clear lineage. In this case, the data is not highly governed in terms of business rules and how everything fits together; the point is you’re allowing your business users to figure it out and add context at the point of analysis.
Transformation layer: For a more governed approach, you can integrate your data into a dimensional data warehouse. The main difference in this situation is that your data will be transformed to combine disparate sources together into a business context. This requires business users to understand the logic and data governance around the data before they can optimize it for analytics. A data transformation layer is very important because it establishes the rules and adds context, and then translates that data into information in a reliable, consistent, governed way.
Having a two-tiered approach where you have a staging layer for your data sources before the data warehouse layer will give you the best of both worlds. It’s important to define, however, who will use each layer and for what purpose. Business requirements should determine the best way to proceed with a data integration solution.
What Are the Best Practices for Implementing a Data Integration Solution?
Data integration should not be a bottleneck to your business operations. In fact, you should view your data integration as a business solution, not just a technical one.
Your data architecture should always support the ability of your people to access data, and data integration is a key function of your data architecture.
Here are some of our data integration best practices:
Build the business case: You need to define the “why” before building a data integration solution. It is not enough to say that you want to reduce risk and increase efficiency by reducing manual touch, even though that is a real benefit. Everyone working on the integration needs to know what business problem it will solve and the value of the data integration in business terms. When everyone involved has this context, all subsequent decision-making will be better.
Let the principles guide the process: When you’ve answered the “why”, then you can begin to think about the how.
A common mistake is over-engineering a data integration solution.
When you don’t identify the “why”, you run the risk of making the solution too complicated or too simple, where it is not scalable, secure, or stable.
Having baseline principles and expectations for data integrations helps guide technical decisions along the way. Example principles are things like “your data integration solution should always: protect against data loss, have a component of automation, and reduce risk.”
Another principle should be to maintain your metadata. Metadata allows you to keep track of what happens to your data through an integration—what was sent and where —so you can identify issues along the way. It helps you understand areas for improvement, measure data quality, and mitigate risk.
You can leverage similar metadata logging processes and patterns across data integrations to speed up design and prevent developers from recreating the wheel with each new interface.
Assign roles for accountability: You need clearly assigned roles for a data integration—a stakeholder who owns the integration, as well as a steward who manages the day-to-day of a data integration solution. This combination of responsibility and maintenance ensures long-term success.
Select the right tools and techniques: There are lots of options here, but it ultimately comes down to understanding your business needs and business requirements. Below are a few things you should consider when making your selections.
Finding the Right Data Integration Tools and Techniques
The landscape of data integration is going through an overhaul right now; it is a long-overdue shift toward the flexibility and scalability that cloud-based architecture and tools have brought us. But with this shift comes confusion and decision fatigue.
Here are some questions you should answer as you decide which tool and technique is best suited for your business needs:
Should we ingest our data into a cloud data warehouse?
While remaining on-premises for your transactional applications can make sense in some cases—stability, sunk infrastructure cost, familiarity, etc.—it is much more difficult to justify leaving your analytics stack on-premises. The cloud brings advantages to your analytics stack that are difficult, or even impossible, to perform in an on-premise environment, including the ability to scale compute or storage with a click of a button, ingest new data sources in minutes, and take advantage of SaaS offerings. It has never been easier to create a unified view of all your data.
So, should you ingest your data into a cloud data warehouse? Ask yourself:
Do you ever worry about hitting storage limits in your current analytics stack?
Do your queries take way too long? Do they frequently strain the limits of the compute that you can throw at them?
Do you have multiple disparate data sources that are hard to wrangle together into a single cohesive analytics platform?
Wouldn’t it be nice not to have to worry about ingestion?
If you answered yes to any of the questions above, it might be time to move to a modern data stack.
Which cloud provider is best for what I want to do?
This depends again on your business needs, plus your current environment. Each cloud provider has certain high-level benefits that we’ve identified below.
Amazon Web Services (AWS): The market leader, AWS, has the largest number of services across storage, compute, database, analytics, IoT, security, etc. Their biggest advantage is their ability to do almost everything.
Microsoft Azure: Azure is a close second when it comes to service offerings in the cloud. Many customers already on SQL Server will find the bridge to the cloud is closer than they think. Active Directory and Office 365 integration also helps with the transition.
Google Cloud Platform (GCP): GCP is a fierce challenger to Azure and AWS. They excel at all things open-source and have some of the best functionality around containers. Their cloud data warehouse—BigQuery—is a market leader when it comes to serverless cloud data warehouses. GCP also has native integrations with Google Workspace and services like Google Analytics.
How should I ingest my data?
There are many ways of ingesting data into the data warehouse. The tooling decision will vary depending on the following questions: Are you going to use a data lake? What are your cost sensitivities? How frequently will the data be refreshed? Each of these answers will help in narrowing down your options.
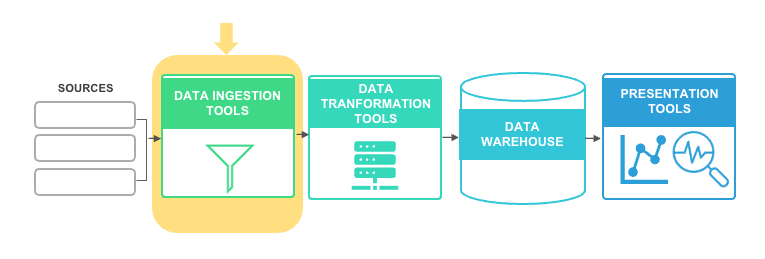
Data ingestion is the process by which data is loaded from various sources to a storage medium—such as a data warehouse or a data lake—where it can be accessed, used, and analyzed.
Here are some data ingestion tools that we frequently use with our clients to build out the persistent staging layer:
Fivetran: Automated data ingestion. I like to describe Fivetran as “the world’s best data engineer for half the price and no hassle”. It is easy to use and can help kickstart analytics projects by clearing the ingestion hurdle. Fivetran offers a free trial and is used by organizations both large and small.
Serverless Python: Serverless computing as an execution framework with the ability to dynamically allocate compute is a key feature of cloud infrastructure. We have developed our own method of ingesting data into a cloud data warehouse using Python and taking advantage of the serverless compute offered by GCP, AWS, and Azure. This requires expertise not required by the automated tooling, but it is a great way to save on costs if you have the skills available to support it.
Airbyte: Open-source data ingestion platform with a continuously evolving set of connectors. You can install and manage the open-source version yourself, or there is Airbyte Cloud, which is fully managed.
Qlik Replicate: A great option for data replication within or out of the Qlik ecosystem. It can connect to many legacy RDBMS as well as mainframe applications. It even offers connectivity to SAP.
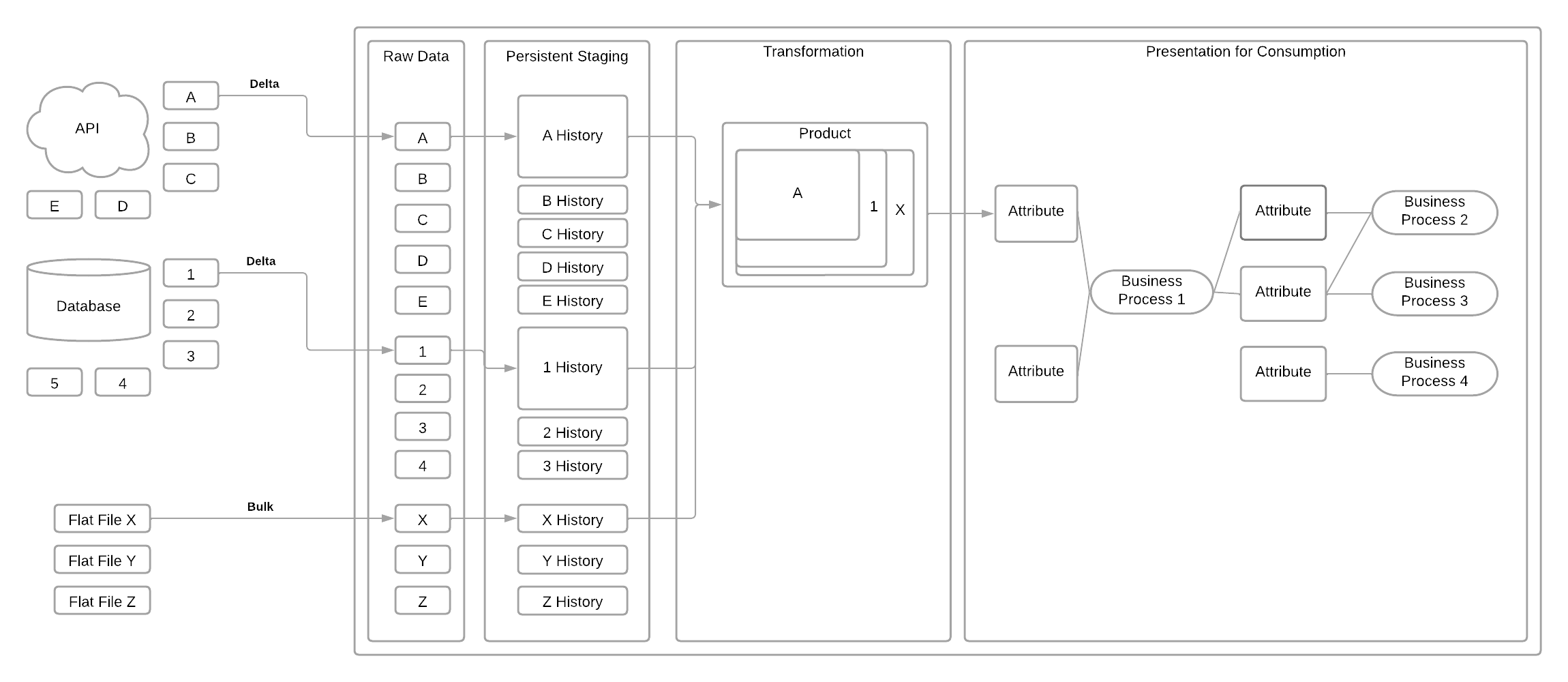
Example transformation combining attributes from multiple source systems into a dimensional model.
Once you have the data extracted from your operational systems and landed in a persistent staging area, you should transform the data for analytics use cases. Often, source data is structured in a way that is optimized for transactional use cases or the needs of that specific system. These data structures can be difficult to work with when it comes to repurposing the data for analytics or machine learning. Dimensional models designed around specific business processes will make it easy for users to understand and interact with your data.
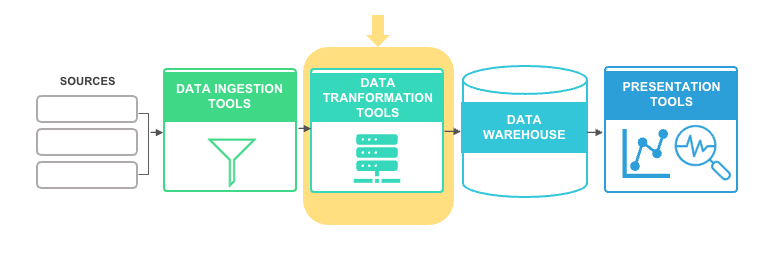
What tools should I use to transform my data?
As with data ingestion tools, picking a data transformation tool will come down to your cloud environment, preference for low- or no-code applications, the skillsets of your development team, and whether you value open-source technologies.
Data transformation is the process of changing data formats and applying business logic to your data.
Here are some data transformation tools that can minimize development overhead and get you going quickly:
DBT: A development framework that combines modular SQL with software engineering best practices. This tool is a favorite of many data engineers. DBT automatically generates documentation, which is a nice feature, but it also allows you to apply version control, testing, and continuous integration/continuous deployment to analytics code. Enhanced features such as orchestration are available in dbt Cloud, or they can be self-hosted through dbt Core.
Azure Data Factory: ADF is a good option for those in Azure who want to stay entirely in the Microsoft stack and value native integrations with other Azure services. ADF has a web UI with a drag-and-drop interface for low- or no-code options. You can also migrate existing SSIS workloads to ADF, making the transition from on-prem to the cloud easier.
Apache Airflow: A project of the Apache Software Foundation, Airflow is a platform to programmatically author, schedule, and monitor workflows. Airflow pipelines are configured as Python code, allowing for dynamic pipeline generation. Airflow is a great option for organizations that like to get their hands dirty with code. There are many managed versions of Airflow from cloud providers that remove the provisioning and management of the underlying infrastructure.
Coalesce.io: Coalesce is a new and exciting tool on the market that is built exclusively for Snowflake. It has a column-aware architecture that can accelerate data transformations and the creation of database objects. Coalesce also has a code-first but GUI-driven user experience with reusable data patterns.
Where should I store my data warehouse?
In today’s ecosystem, there’s no good reason to leave your data warehouse on-premises. The flexibility afforded by horizontal and vertical scaling of compute and near-limitless storage that a cloud data warehouse brings is unparalleled by any other approach. This can help democratize data access across your entire organization.
A data warehouse is a highly governed centralized repository of modeled data sourced from all kinds of different places. Data is stored in the language of the business, providing reliable, consistent, and quality-rich information.
In terms of which cloud data warehouse is better suited for your needs, below are some of our favorites and why you might use them.
Snowflake: With de-coupled storage and compute, you’re able to scale up or down at the click of a button, which makes running parallel workstreams incredibly easy. It provides a robust security environment along with great integrations with other tools, and runs on top of AWS, GCP, and Azure, allowing you to be cloud provider agnostic.
Redshift (AWS’s cloud data warehouse offering built on top of PostgreSQL): It typically requires more hands-on management than Snowflake, but allows you to fine-tune your environment based on your needs. If you have skilled DBAs or cloud infrastructure specialistswho can get into the weeds, this is a good option.
BigQuery (GCP’s offering in the cloud data warehouse space): Their model is entirely serverless, which means that you’re charged based on the compute run by each query (i.e., by how much data is processed by your queries). It integrates well with Looker, and you can create and execute machine learning models directly in BigQuery using SQL.
Azure Synapse: This is Microsoft’s data warehousing platform with similar auto-scaling functionality to its rivals. Announced as an evolution of Azure SQL Data Warehouse, you can take advantage of the serverless or provisioned resources option. Built on top of Polybase, it allows access to structured and unstructured data sources.
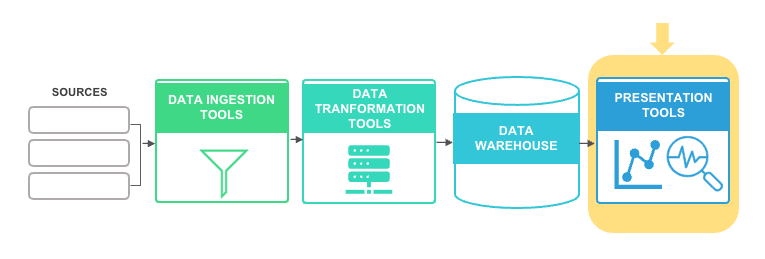
What other tools do I need to consider?
Presentation tools help business users make more informed decisions by delivering reports and dashboards to help them analyze data and actionable information.
After you have blended multiple source systems together and transformed your data into an analytics-ready format, you need to provide an easy way for your business users to interact with it. This is where you will need to implement a BI tool or platform where you can create rich visualizations and quickly gain insights to stay ahead of your competition.
Data integration might seem complex, but with a clearer understanding of how to approach the process, how to implement it, and how to pick the best tools and techniques, you are one step closer to realizing the value of your data and making it accessible and actionable when it matters most.
Talk With a Data Analytics Expert
Key Takeaways
Data integration connects siloed data sources to create a unified, analytics-ready view
Siloed data creates challenges like duplicate efforts, lack of context, and poor data quality
Integration adds context and perspective to data, making it more valuable to business users
Two main approaches are a persistent staging layer or a governed transformation layer
Many organizations benefit from a hybrid approach with both raw and transformed layers
Successful integration starts with a clearly defined business case and guiding principles
Principles should include protecting against data loss, automation, and metadata tracking
Assigning clear roles improves accountability and ensures long-term solution maintenance
Cloud data warehouses offer flexibility, scalability, and faster analytics than on-prem setups
Modern tools like Fivetran, DBT, Airbyte, and Coalesce accelerate ingestion and transformation
Tool selection should align with business goals, data volumes, team skills, and cloud preferences
Cloud providers like AWS, Azure, and GCP each offer unique strengths for integration needs
Business intelligence tools enable end users to analyze integrated data and drive decisions
Data integration is foundational to enabling data-driven decision-making across the business
Do you make business decisions based on spreadsheets or siloed databases with non-standardized structures and formats? Do you see inconsistency in data across business units? Do you have difficulties deciding permissions and access levels to restricted business data? In this blog, we discuss how these problems can be addressed with a data warehouse and provide…
For your analytics solution to effectively drive decision making, you need clean data and a flexible data infrastructure that supports all of your current and future analytics needs. Everything you want to do when it comes to analytics – from the advanced stuff, like data science and machine learning, to the basics – hinges on…
In this blog, we provide insight as to why manual data practices can bring unnecessary risk to your projects and how to overcome those obstacles. Why Manual Processes Aren’t “Good Enough” While every analyst knows that automation practices lead to better data quality, more accurate reporting, and ultimately the ability for them to focus on…
Whether you are considering moving your data to the cloud, are in the process of choosing a cloud platform, or are optimizing existing cloud resources — you need the right strategy in place so you can reap all the benefits the cloud can offer. This blog will guide you through the process of moving your…
To thrive in today’s marketplace, you need to turn your data into your company’s strongest asset. But in order to really take advantage of your data, you need a modern data and analytics ecosystem that is scalable, agile, and future ready. Most organizations aim to be one step ahead of the competition—able to make more…
To solve modern data problems and to take advantage of modern data opportunities, you need a modern approach to data management. Many organizations buy and implement new modern technology solutions in the hope that their data problems will be magically solved overnight, but they quickly find that technology alone is not enough. Other organizations adopt…
Data Strategy Session
To thrive with your data, your people, processes, and technology must all be data-focused. This may sound daunting, but we can help you get there. Sign up to meet with one of our analytics experts who will review your data struggles and help map out steps to achieve data-driven decision making.
Fill out this form to get a 30-minute Data Strategy Session with one of our analytics experts.
Contact Us
Have questions? Tell us a little about yourself, and we'll get in touch as soon as we can.




![Cloud Migration Strategy Guide [and Checklist]](https://www.analytics8.com/wp-content/uploads/2026/03/Cloud-Migration-Checklist-Thumbnail.png)

