
Last updated on July 15, 2026
Best-in-Breed Data Stack: BigQuery, dbt, and Looker
By Josh Goldner
In this blog, we take a deep dive into three best-of-breed platforms within a modern data stack—BigQuery, dbt, and Looker—and explain what benefits this data stack can bring to your organization, and why you should consider making the switch.
As a data professional, it can be daunting—exhausting even—to keep tabs on every tool that currently exists in what is commonly referred to as the modern data stack. With new tools on the market every day, it can be a full-time job just to keep up to date with functionality, changes to platforms, new methods, best practices, and everything in between.
At the end of the day, most organizations are looking for the simplest solutions that will solve their current and future challenges with data. Fortunately, there is a best-in-breed data stack that rises to this challenge: BigQuery, dbt, and Looker.
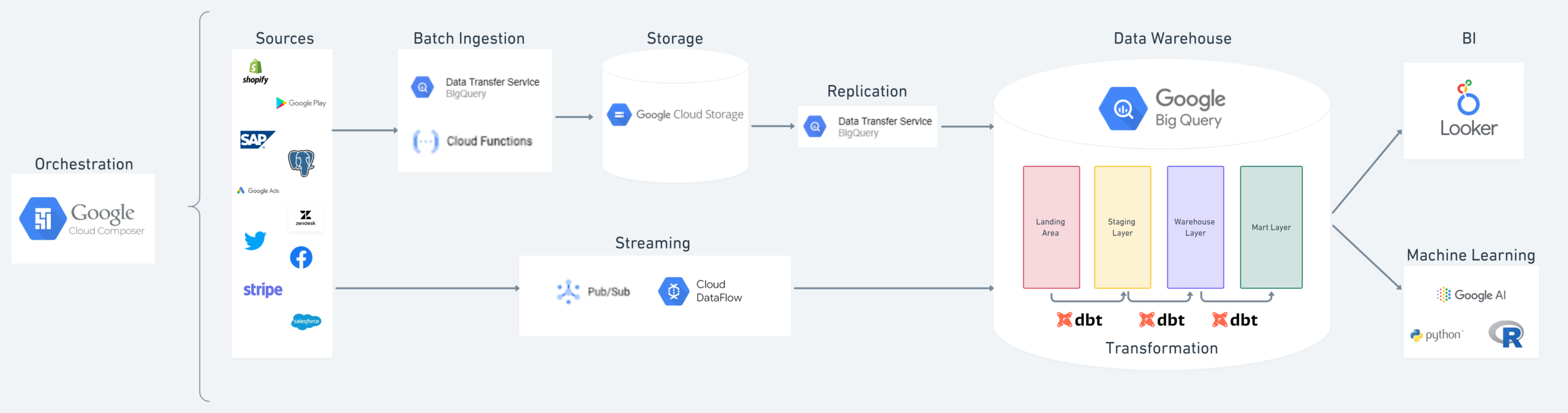
BigQuery, dbt, and Looker are impressive on their own, but their real power is unleashed when combined. Before going into the benefits of a combined data stack, let’s look at what each platform brings to the table.
The Strengths and Benefits of BigQuery as a Data Warehouse
BigQuery sets itself apart as a data warehouse in three ways: effortless serverless infrastructure, affordability, and machine learning capabilities.
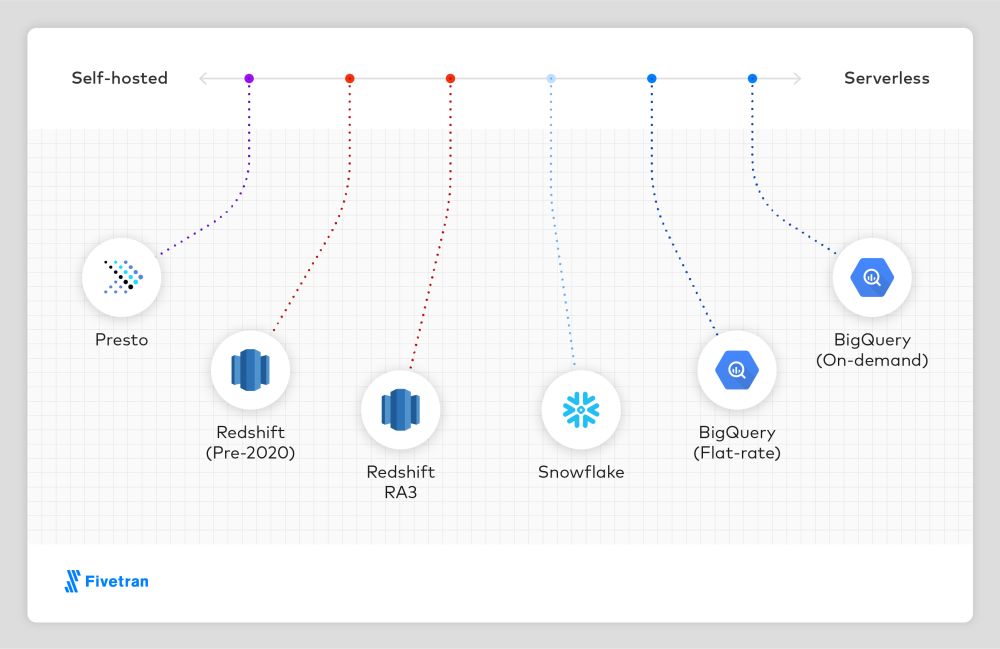
The Strengths and Benefits of dbt as a Data Transformation Tool
dbt provides an advanced development framework to transform data on top of cloud platforms. dbt’s transformations are centered around SQL which has tightly integrated many data teams. dbt Cloud comes with many features including version control integrations, an intuitive development IDE, a centralized documentation hub, orchestration, and advanced testing capabilities.
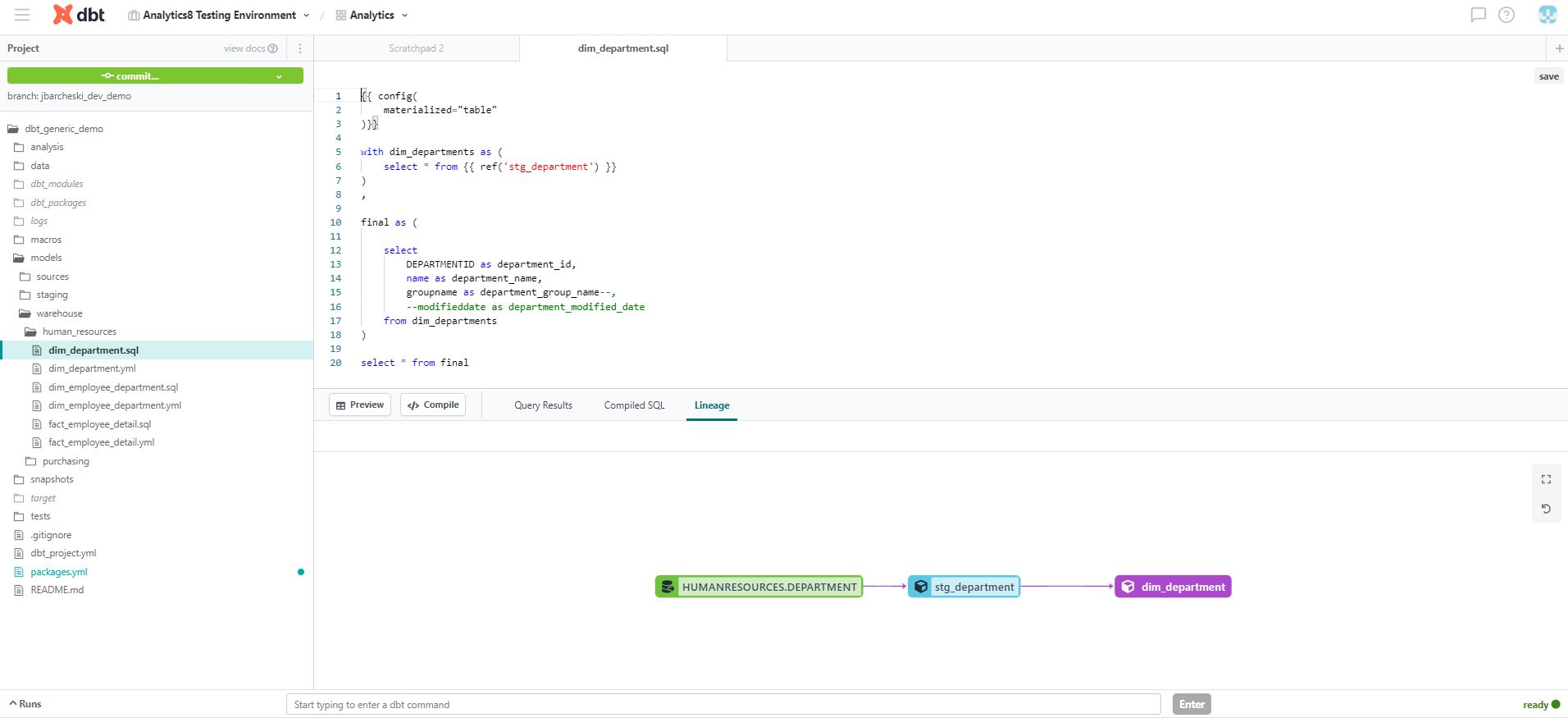

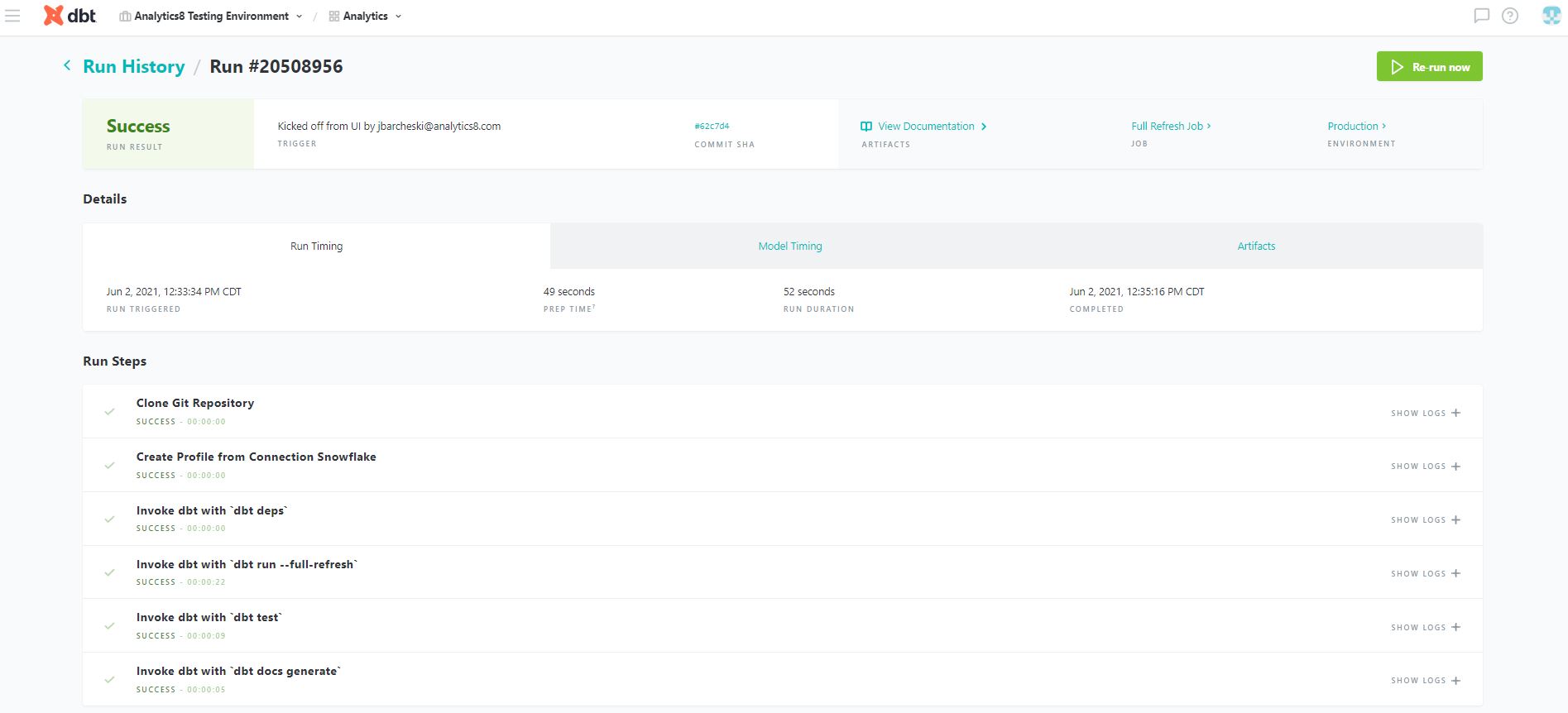

The Strengths and Benefits of Looker as a Business Intelligence (BI) and Reporting Platform
Looker brings best-in-class data governance, API-driven development, and embedded analytics capabilities to enable reporting and dashboarding within the modern data stack—all this and more while maintaining unparalleled security models.
What Makes BigQuery, dbt, and Looker a Best-in-Breed Data Stack?
While each of these tools on their own provide significant benefits, the three work together in a multitude of ways to provide scalability, performance, reusability, and efficiency across the board.
The Integration Between BigQuery and dbt
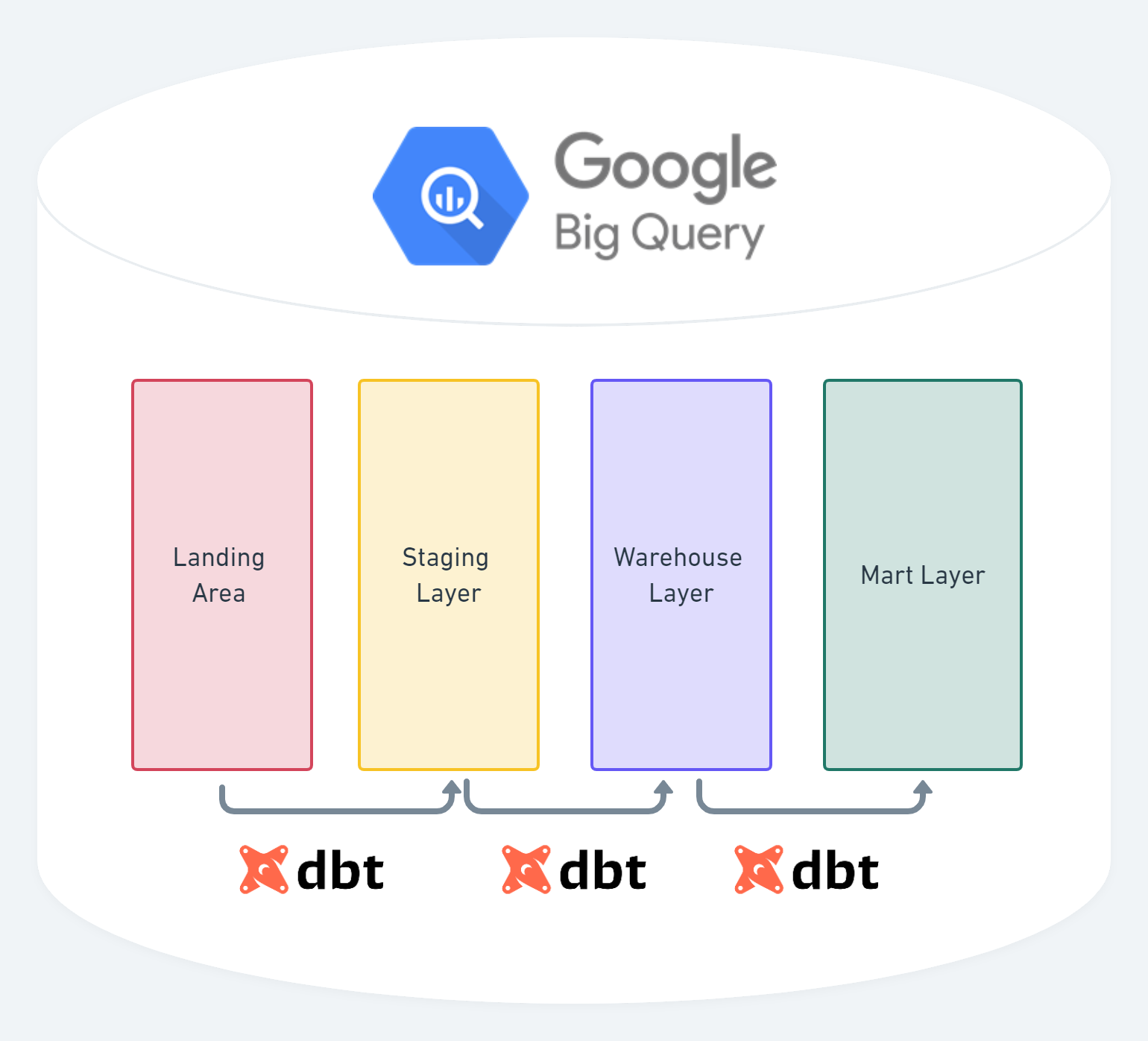
Alone, BigQuery is an incredible tool thanks to its advanced features and petabyte scalability. However, as many teams grow, it becomes extremely difficult to manage transformations in BigQuery alone whether you use views, scheduled queries, or an alternative solution. Having an advanced transformation framework that accelerates your development, documentation, testing, and deployment processes should be a priority, and combining dbt with BigQuery fills this gap and unleashes synergies as they integrate flawlessly together.
In addition to the features available through dbt, you also can take advantage of unique open-source packages designed specifically for BigQuery and dbt. For example, “dbt_ml” is an open-source package that enables teams to automate training, auditing, and using BigQuery Models.
Since dbt micro focuses on transformations on top of BigQuery, it allows you to still choose the best tools to complete your data stack and address your specific needs. A large reason many of our customers love dbt is because they never have to choose a one-size fits all approach.
The Integration Between BigQuery and Looker
BigQuery with Looker combines the scalability and flexibility of each tool to allow users to leverage all sizes and types of data—nested, flattened, big, small, and everything in between— your organization has now or will in the future. As your data use cases grow, so do these tools.
Additionally, you can use BigQuery’s cost estimator within Looker to monitor spend. As users bring in data from all over the known (and unknown) data-verse, use dbt and BigQuery to pull that data into a central location and let Looker write the SQL needed to analyze it—no need for end users to know how to account for any special type of data or write SQL. Looker sits on top of BigQuery taking full advantage of everything it has to offer as end users are analyzing their data in a cost-effective, managed, and curated environment.
The Integration Between Looker and dbt
Looker with dbt takes data governance and transformation to a whole new level. You can use dbt to model business definitions, aggregations, heavy computational metrics, and you can use LookML to put the finishing touches on your data, prototype data model changes, define metrics or definitions that require end user interaction, and implement joins and explores (how users interact with the data).
While these tools are more than enough to get you started, when you’re ready to take it to the next level, put a third-party tool (like Spectacles) on top of Looker and dbt to let you know how, where, and what will be affected in Looker each time you make a change in dbt. Now, instead of your end users sounding the alarm that things are broken (or worse, incorrect and nobody knows), developers know exactly what will happen when they implement. The point is that each of these tools are ready to take your implementation to the next level as your data needs mature.
Why You Should Consider a BigQuery, dbt, Looker Stack
Organizations want to make sure the data stack can integrate with their current data sources, is future proof, cost-effective, and can handle all their main and edge cases of data and analytics. Not only do all three of these tools integrate and play nicely with each other and the other tools in your data arsenal, but when used in concert, they allow you to control every aspect of your data including security, data governance, and integration with third-part tools downstream of even Looker.
And while all three of these tools might not be under the same flag, getting them to work together is not a huge undertaking or something that requires a ton of pre-work.
Futureproof data stack: All these tools were born in the cloud for the cloud:
Cost-effective data stack: Every data stack has implementation costs, but there are other costs you need to consider, specifically around operating costs including:
Utilizing all the features in a BigQuery, dbt, and Looker stack allows you to set limits, use archiving features to automatically reduce cost, and let you pull in more data for free as use cases evolve—as well, by default—give you generous free tiers that don’t start charging until you reach them.
Data stack that can handle all main and edge cases of data and analytics: There isn’t much that these three tools can’t do together. If there is, odds are there is another tool in their collective ecosystem that can either quickly bolt on or can be custom-built using their development framework, including:
We’ve only scratched the surface as far as what this data stack can do, and how it can help your business grow. BigQuery, dbt, and Looker allow you and your organization to take advantage of best-in-breed technology without sacrificing ease of use and is already set up to grow as your organization does.


![Cloud Migration Strategy Guide [and Checklist]](https://www.analytics8.com/wp-content/uploads/2026/03/Cloud-Migration-Checklist-Thumbnail.png)


