
Last updated on July 28, 2021
dbt Overview: What is dbt and What Can It Do for My Data Pipeline?
By Simon Collis
There are many tools on the market to help your organization transform data and make it accessible for business users. One that we recommend and often use dbt—focuses solely on making the process of transforming data simpler and faster. In this blog we will discuss what dbt is, how it can transform the way your organization curates its data for decision making, and how you can get started with using dbt.
Data plays an instrumental role in decision-making for organizations. As the volume of data increases, so does the need to make it accessible to everyone within your organization to use. However, because there is a shortage of data engineers in the marketplace, for most organizations, there isn’t enough time or resources available to curate data and make data analytics-ready. Disjointed sources, data quality issues, and inconsistent definitions for metrics and business attributes lead to confusion, redundant efforts, and poor information being distributed for decision making. Transforming your data allows you to integrate, clean, de-duplicate, restructure, filter, aggregate, and join your data—enabling your organization to develop valuable, trustworthy insights through analytics and reporting. There are many tools on the market to help you do this, but one in particular—dbt—simplifies and speeds up the process of transforming data and building data pipelines. In this blog, we cover:- What is dbt?↵
- How is dbt Different Than Other Tools?↵
- What Can dbt Do for My Data Pipeline?↵
- How Can I Get Started with dbt?↵
- Training to Learn How to Use dbt↵
What is dbt?
According to dbt, the tool is a development framework that combines modular SQL with software engineering best practices to make data transformation reliable, fast, and fun. dbt makes data engineering activities accessible to people with data analyst skills to transform the data in the warehouse using simple select statements, effectively creating your entire transformation process with code. You can write custom business logic using SQL, automate data quality testing, deploy the code, and deliver trusted data with data documentation side-by-side with the code. This is more important today than ever due to the shortage of data engineering professionals in the marketplace. Anyone who knows SQL can now build production-grade data pipelines, reducing the barrier to entry that previously limited staffing capabilities for legacy technologies. In short, dbt turns your data analysts into engineers and allows them to own the entire analytics engineering workflow.How is dbt Different Than Other Tools?
With dbt, anyone who knows how to write SQL SELECT statements has the power to build models, write tests, and schedule jobs to produce reliable, actionable datasets for analytics. The tool acts as an orchestration layer on top of your data warehouse to improve and accelerate your data transformation and integration process. dbt works by pushing down your code—doing all the calculations at the database level—making the entire transformation process faster, more secure, and easier to maintain. dbt is easy to use for anyone who knows SQL—you don’t need to have a high-powered data engineering skillset to build data pipelines anymore.Hear why dbt is the iFit engineering team’s favorite tool and how it helped them drive triple-digit growth for the company:
dbt’s ELT methodology brings increased agility and speed to iFit’s data pipeline. What would have taken months with traditional ETL tools now takes weeks or days.Have a data strategy that isn’t delivering?
Talk to an expert about your dbt needs.What Can dbt Do for My Data Pipeline?
dbt has two core workflows: building data models and testing data models. It fits nicely into the modern data stack and is cloud agnostic, meaning it works within each of the major cloud ecosystems: Azure, GCP, and AWS. With dbt, data analysts take ownership of the entire analytics engineering workflow from writing data transformation code all the way through to deployment and documentation, as well as to becoming better able to promote a data-driven culture within the organization. They can:1. Quickly and easily provide clean, transformed data ready for analysis:
dbt enables data analysts to custom-write transformations through SQL SELECT statements. There is no need to write boilerplate code. This makes data transformation accessible for analysts who don’t have extensive experience in other programming languages.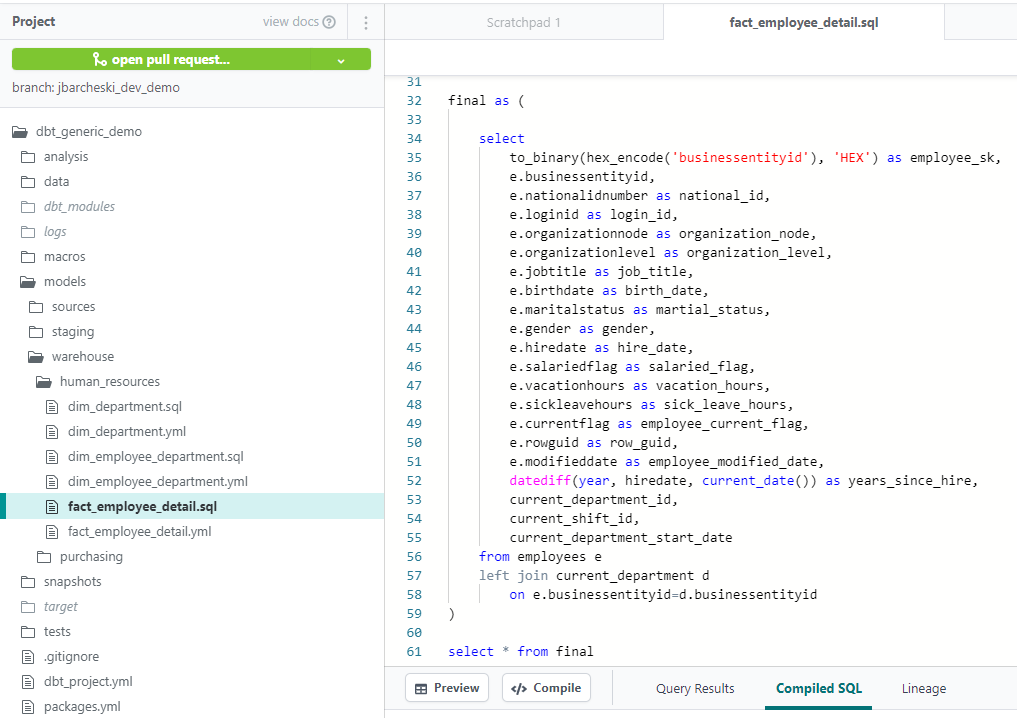
2. Apply software engineering practices—such as modular code, version control, testing, and continuous integration/continuous deployment (CI/CD)—to analytics code:
Continuous integration means less time testing and quicker time to development, especially with dbt Cloud. You don’t need to push an entire repository when there are necessary changes to deploy, but rather just the components that change. You can test all the changes that have been made before deploying your code into production. dbt Cloud also has integration with GitHub for automation of your continuous integration pipelines, so you won’t need to manage your own orchestration, which simplifies the process.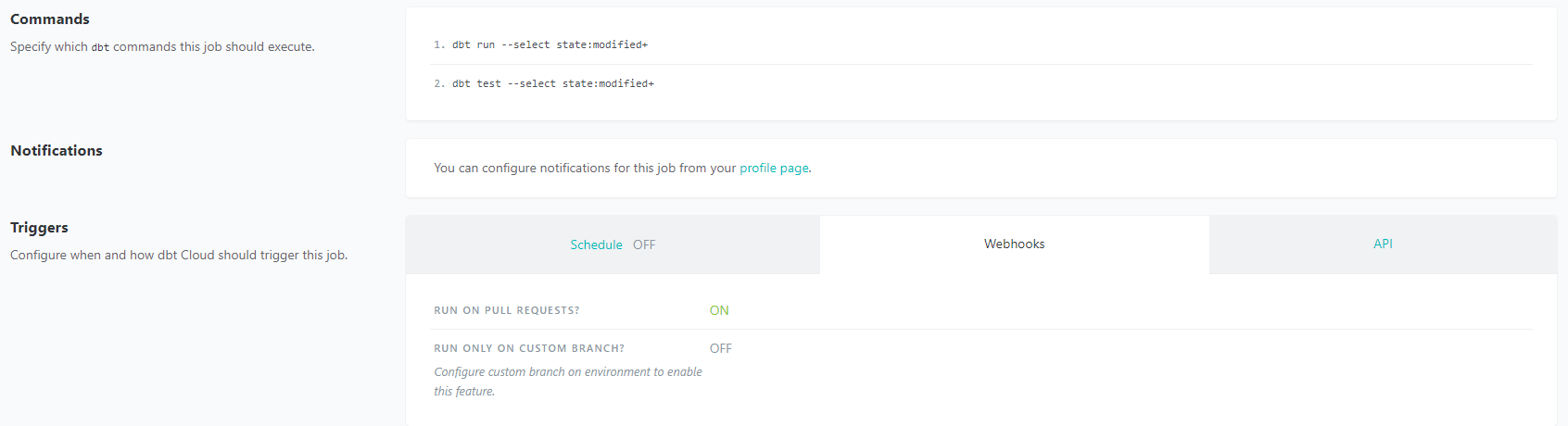
3. Build reusable and modular code using Jinja.
dbt allows you to establish macros and integrate other functions outside of SQL’s capabilities for advanced use cases. Macros in Jinja are pieces of code that can be used multiple times. Instead of starting at the raw data with every analysis, analysts build up reusable data models that can be referenced in subsequent work.
4. Maintain data documentation and definitions within dbt as they build and develop lineage graphs:
Data documentation is accessible, easily updated, and allows you to deliver trusted data across the organization. dbt automatically generates documentation around descriptions, model dependencies, model SQL, sources, and tests. dbt creates lineage graphs of the data pipeline, providing transparency and visibility into what the data is describing, how it was produced, as well as how it maps to business logic.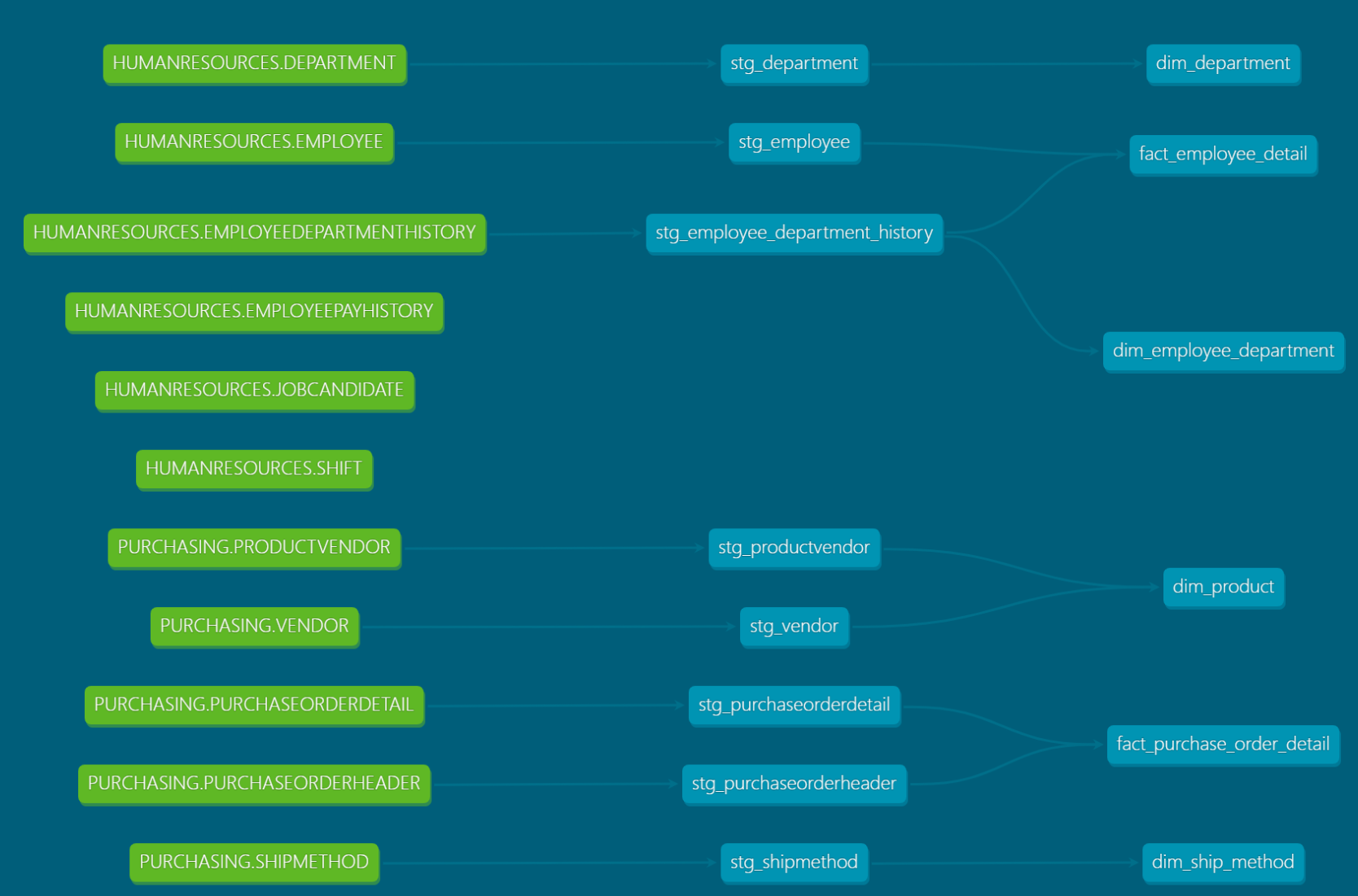
5. Perform simplified data refreshes within dbt Cloud:
There is no need to host an orchestration tool when using dbt Cloud. It includes a feature that provides full autonomy with scheduling production refreshes at whatever cadence the business wants.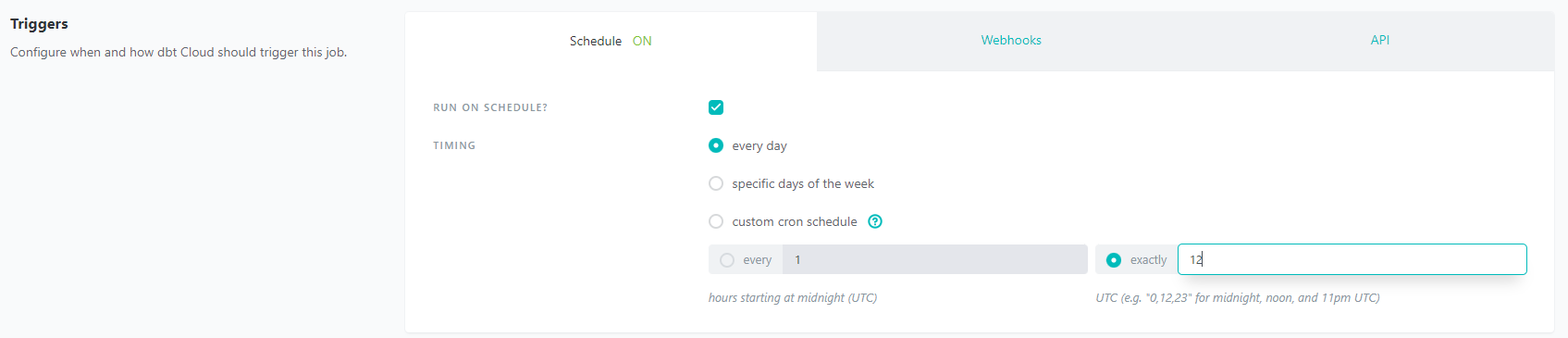
6. Perform automated testing:
dbt comes prebuilt with unique, not null, referential integrity, and accepted value testing. Additionally, you can write your own custom tests using a combination of Jinja and SQL. To apply any test on a given column, you simply reference it under the same YAML file used for documentation for a given table or schema. This makes testing data integrity an almost effortless process.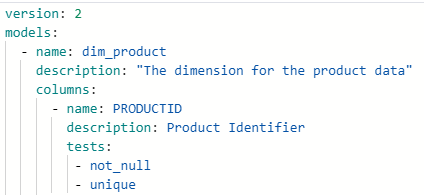
How Can I Get Started with dbt?
Prerequisites to Getting Started with dbt
Before learning dbt, there are three prerequisites that we recommend:- SQL: Since dbt uses SQL as its core language to perform transformations, you must be proficient in using SQL SELECT statements. There are plenty of courses online available if you don’t have this experience, so make sure to find one that gives you the necessary foundation to begin learning dbt.
- Modeling: Like any other data transformation tool, you should have some strategy when it comes to data modeling. This will be critical for the re-usability of code, drilling down, and performance optimization. Don’t just adopt the model of your data sources; we recommend transforming data into the language and structure of the business. Modeling will be essential to structuring your project and finding lasting success.
- Git: If you are interested in learning how to use dbt Core, you will need to be proficient in Git. We recommend finding any course that covers the Git Workflow, Git Branching, and using Git in a team setting. There are lots of great options available online, so explore and find one that you like.
Training to Learn How to Use dbt
There are many ways you can dive in and learn how to use dbt. Here are three tips on the best places to start:- The dbt Labs Free dbt Fundamentals Course: This course is a great starting point for any individual interested in learning the basics of using dbt. This covers many critical concepts like setting up dbt, creating models and tests, generating documentation, deploying your project, and much more.
- The “Getting Started Tutorial” from dbt Labs: Although there is some overlap with concepts from the fundamentals course above, the “Getting Started Tutorial” is a comprehensive hands-on way to learn as you go. There are video series offered for both using dbt Core and dbt Cloud. If you really want to dive in, you can find a sample dataset online to model as you go through the videos. This is a great way to learn how to use dbt in a way that will directly reflect how you would build out a project for your organization.
- Join the dbt Slack Community: This is an active community of thousands of members that range from beginner to advanced. There are channels like #learn-on-demand and #advice-dbt-for-beginners that will be very helpful for a beginner to ask questions as they go through the above resources.
Learn What dbt Can Bring to Databricks
Talk With a Data Analytics Expert
Key Takeaways
- dbt empowers analysts to build and manage data pipelines using SQL, which reduces the need for dedicated data engineers.
- Unlike traditional ETL tools, dbt uses an ELT approach and pushes transformations directly to the data warehouse. This improves speed, scalability, and maintainability.
- Its core capabilities include modular code development, automated testing, integrated CI/CD pipelines, built-in documentation, and clear data lineage tracking.
- dbt works across cloud environments such as AWS, Azure, and GCP, making it easy to integrate with modern data infrastructure.
- To begin using dbt effectively, users should be comfortable with SQL, understand data modeling concepts, and have basic familiarity with Git workflows.
- Free learning resources—including dbt Labs’ Fundamentals course, tutorial videos, and the active Slack community—help users ramp up quickly and confidently.



![Cloud Migration Strategy Guide [and Checklist]](https://www.analytics8.com/wp-content/uploads/2026/03/Cloud-Migration-Checklist-Thumbnail.png)

